L1 Buy after Dump DetectorLevel: 1
Background
The so-called "Buy after Dump" refers to the phenomenon in which the stock price sometimes rebounds temporarily due to the rapid decline in the falling market. The rebound was smaller than the decline, and the downtrend resumed after the rebound.
Function
L1 Buy after Dump Detector is one of my research to see win rate of a "Buy after Dump" chance. The principle is that I use ema() and OHLC to model a whale dump behavior. After the dump wave, I use KDJ to indicate several long entry points.
Key Signal
dump --> whale dump signal
fundready --> it indicate the end of a dump and make fund ready to long entry
longentry --> long entry signal generated from KDJ resonating with dump and fundready signal
Pros and Cons
Pros:
1. it can detect obvious dump and depict the decay of dump wave
2. use resonance to generate long entry
Cons:
1. it may be risky to "buy after dump" which may require take profit method here because the opportunity may be very short
2. KDJ is too sensitive in large time frame and have many long entry signals (the closer to dump wave, the better based on experience)
Remarks
Very interesing stuff, but rare of people trade with such crazy method. I suggest this is ONLY for backtest study of market behavior.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
Wyszukaj w skryptach "THE SCRIPT"

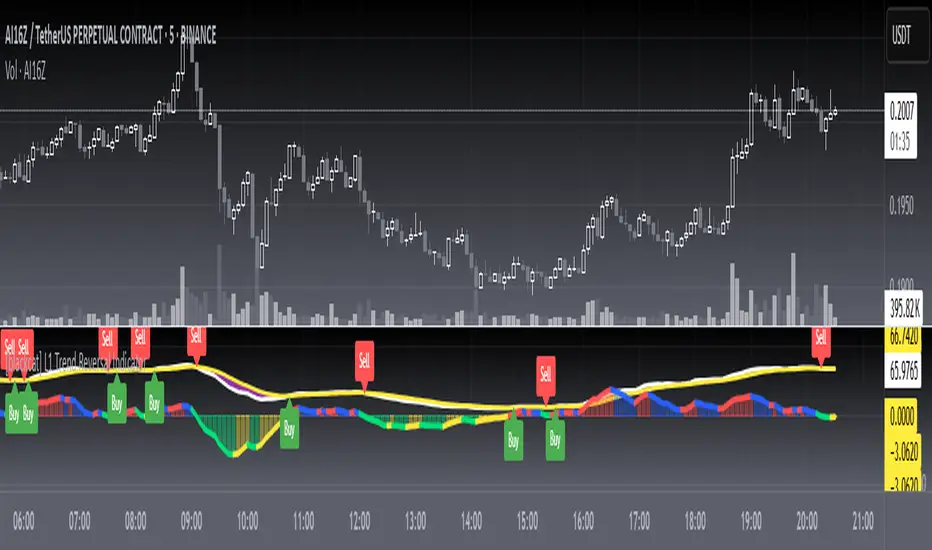
L1 Trend Reversal IndicatorLevel: 1
Background
A trend reversal occurs when the direction of a stock (or a financial trading instrument) changes and moves back in the opposite direction. Uptrends that reverse into downtrends and downtrends that reverse into uptrends are examples of trend reversals.
Function
L1 Trend Reversal Indicator is simple but powerful. It can be used as a basic element for many complex trading system. Although L1 Trend Reversal Indicator can't hold a candle to moving averages in indicating trend reversals, it's good at showing the strength of a trend and trend cycles.
Key Signal
My favoriate trend reversal indicator with histograms
Pros and Cons
Pros:
1. Simple but clear to see the trend reversals
2. Use histogram to indicate sub-time-frame trend changes
Cons:
1. No advanced trading skill is incorporated
2. Need improvements on sideways.
Remarks
Just be simple but powerful
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
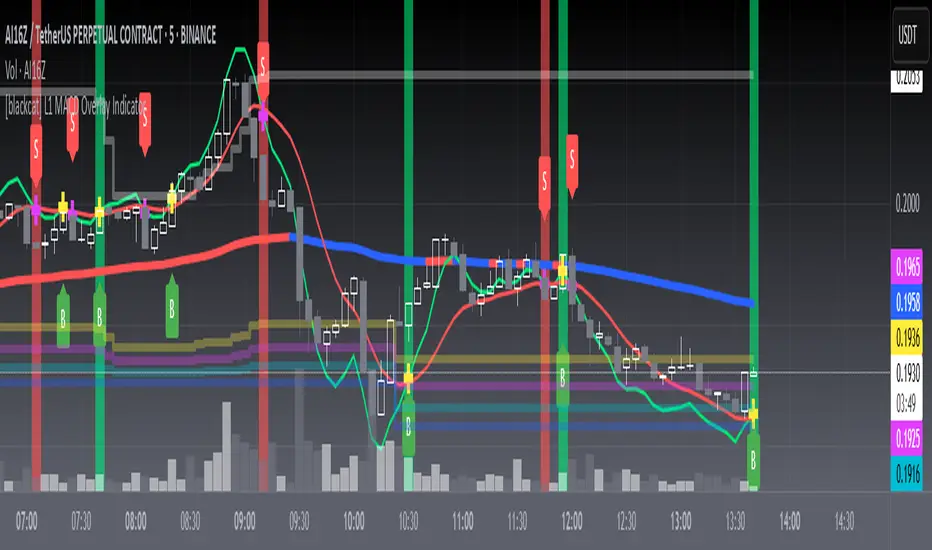
L1 MACD Overlay IndicatorLevel: 1
Background
MACD is a measure of changes in the dynamics between short-term and longer-term price averages. The sign (positive or negative) and the size or MACD line represent the interaction between the two underlying EMAs.
Function
L1 MACD Overlay Indicator is a MACD indicator for main chart. The lime and red color EMAs are the DIFF and DEA signal. I want to plot a contant "Zero Line" line in main chart but failed. So, I use dyanmic color bands to inidcate the "Zero line" in traditioanl MACD. It is not static but a dynamic one.
Key Signal
wdiff --> MACD DIFF
wdea --> MACD DEA
th191 --> zero line
th886 --> zero line
th946 --> zero line
bot --> zero line
Pros and Cons
Pros:
1. main chart MACD
2. easier observation with candles
Cons:
1. I cannot draw static zero line in main chart with PINE, so I draw dyanmic "Zero"
2. No diff-dea histograms
Remarks
I cannot draw static zero line in main chart with PINE, so I draw dyanmic "Zero"
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
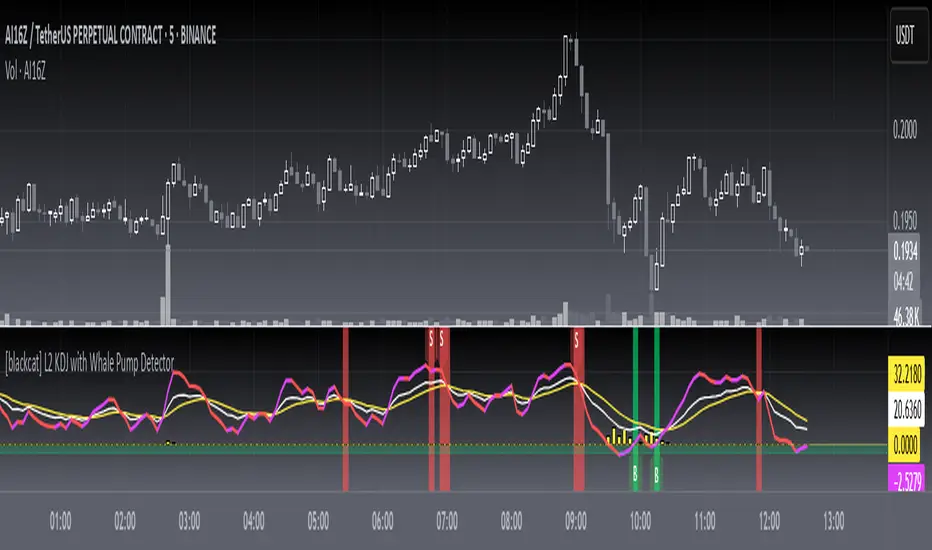
L2 KDJ with Whale Pump DetectorLevel: 2
Background
One of the biggest differences between cryptocurrency and traditional financial markets is that cryptocurrency is based on blockchain technology. Individual investors can discover the direction of the flow of large funds through on-chain transfers. These large funds are often referred to as Whale. Whale can have a significant impact on the price movements of cryptocurrencies, especially Bitcoin . Therefore, how to monitor Whale trends is of great significance both in terms of fundamentals and technical aspects.
The KDJ oscillator display consists of 3 lines (K, D and J - hence the name of the display) and 2 levels. K and D are the same lines you see when using the stochastic oscillator. The J line in turn represents the deviation of the D value from the K value. The convergence of these lines indicates new trading opportunities. Just like the Stochastic Oscillator, oversold and overbought levels correspond to the times when the trend is likely to reverse.
Function
L2 KDJ with Whale Pump Detector is a composite indicator that combines both KDJ and Whale Pump Detector. By virtue of this, fake signal of KDJ can be filtered out to some degree.
Key Signal
whalepump --> whale buy behavior will be detected and displayed in yellow histograms
k --> k value of a stochastic oscillator
d --> d value of a stochastic oscillator
j --> the deviation of the d value from the d value of a stochastic oscillator
Pros and Cons
Pros:
1. filter out KDJ fake signal by introducing whale buy/pump detector
2. J value can be used to detect overbought and oversold regions
Cons:
1. It works better in small time frame and sideways. Extreme long or short conditions may cause KDJ staturate.
2. It can only indicate in current time frame, larger time frame trend info is missing.
Remarks
Composite KDJ+Whale Pump Detector. Works fine in 15mins time frame.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
L1 Composite RSI-William%R IndicatorLevel: 1
Background
The Relative Strength Index (RSI) developed by J. Welles Wilder is a pulse oscillator that measures the speed and change in price movements. The RSI hovers between zero and 100. Traditionally, the RSI is considered overbought when it is above 70 and oversold when it is below 30. Signals can be generated by looking for divergences and error fluctuations. RSI can also be used to identify the general trend.
Williams% R, also known as the Williams Percent Range, is a type of momentum indicator that moves between 0 and -100 and measures overbought and oversold levels. The Williams% R can be used to find entry and exit points in the market. The indicator is very similar to the stochastic oscillator and is used in the same way.
Function
L1 Composite RSI-William%R Indicator combines both RSI and William%R indicator to indicate long and short entries.
Key Signal
rsi1 --> rsi in white
wr1 --> William%R in yellow
bull --> long entry in lime
Pros and Cons
Pros:
1. resonance of RSI and William%R will provide better long and short entry signal
2. use 'bull' to indicate a long entry zone
Cons:
1. It is sensitive to fluctuations
2. More independent long and short entries should be considered
Remarks
Composite RSI+William%R
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

L1 Mid-Term Swing Oscillator v1Level: 1
Background
Oscillators are widely used set of technical analysis indicators. They are popular primarily for their ability to alert of a possible trend change before that change manifests itself in price and volume . They should work best in times of sideways markets.
Function
L1 Short-Mid-Long-Term Swing Oscillator puts three terms of oscillators to cover short-term, middle-term and long-term oscillators at the same time. By resonating all these three oscillators, short-term scalping signal and middle term swing signal are disclosed. You can see both short and mid term signal under one indicator which give you more confidence to follow the trend.
Key Signal
I didn't handle the key signals well. I piled up all the useful signals I found, and it is really difficult to classify them one by one. I feel tired when I think about this problem. Therefore, the code of the overall signal is rather confusing, sorry.
Pros and Cons
Pros:
1. Three oscillators are used to cover short, mid, long term oscillations.
2. Short-Mid term resonance can be observed to have higher confidence level.
3. Use single indicator for scalping and swing trading is possible.
Cons:
1. No deep dive into very accurate long and short entries.
2. A trade off between sensitivity and stability may be needed by traders' subjective judge.
Remarks
I enjoyed the fun of put three different oscillator together to cover short, mid, long terms. But how to use them perfectly is really more brainstorming.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

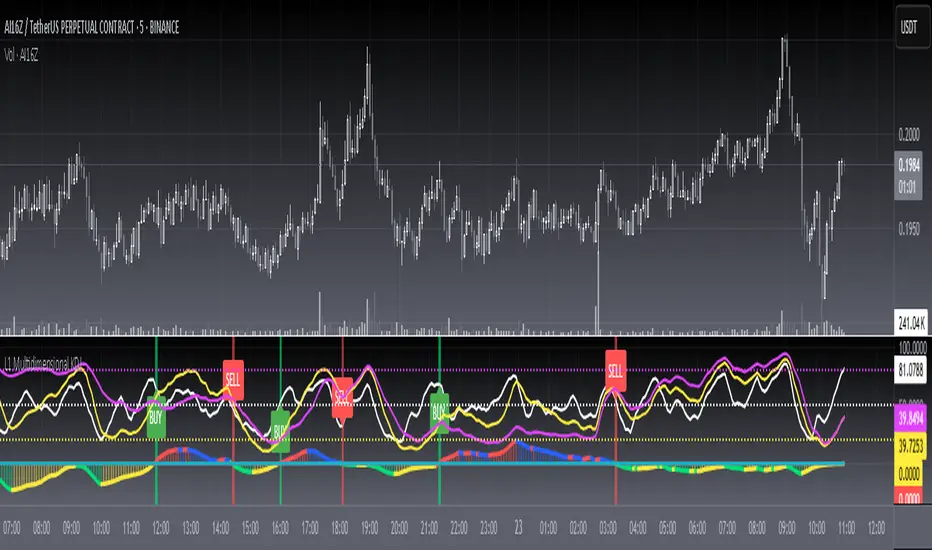
L1 Multidimensional KDJLevel: 1
Background
The KDJ oscillator display consists of 3 lines (K, D and J - hence the name of the display) and 2 levels. K and D are the same lines you see when using the stochastic oscillator. The J line in turn represents the deviation of the D value from the K value. The convergence of these lines indicates new trading opportunities. Just like the Stochastic Oscillator, oversold and overbought levels correspond to the times when the trend is likely to reverse.
Function
L1 Multidimensional KDJ utilizes multiple KDJ modeling across multiple time frames. In this instance, it covers three time frames as day, week and month. Although it is named like that, one can deduce and use it in small time frames e.g. 15mins (day), 60mins (week) and 4H (month) because KDJ oscillator is commonly used for small time frames across various markets.
Key Signal
kd --> day K value
kw --> week K value
km --> month K value
dd --> day D value
dw --> week D value
dm --> month D value
divergence --> divergence among day, week, month D values
resonance --> all three time frame D values are in the same direction
Pros and Cons
Pros:
1. Enable multidimensional KDJ,especially D value comparisons
2. divergence and resoanance among different time frame KDJ can be disclosed
Cons:
1. It may satruate for extreme conditions of long and short.
2. Not accurate for long and short entries by resonance effect.
Remarks
Bring about multiple time frames into consideration of KDJ is novel.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
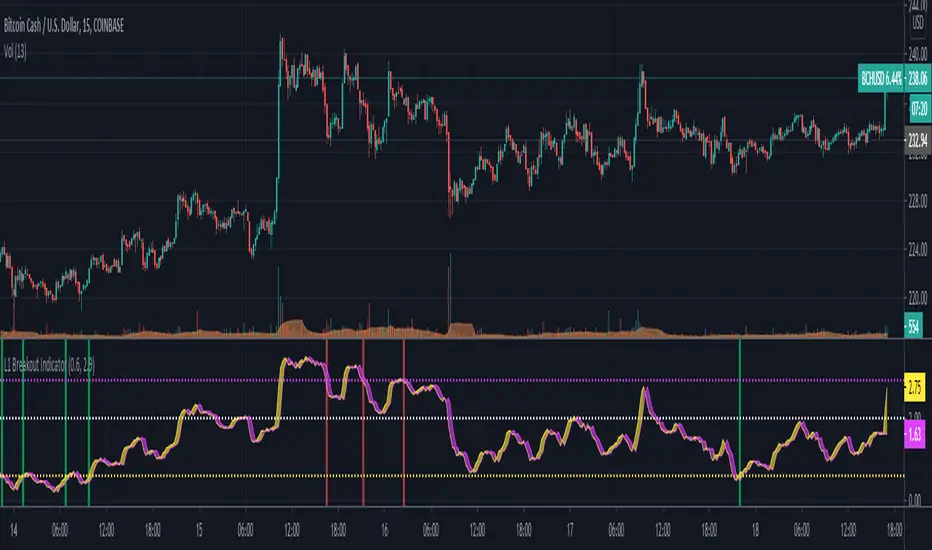
L1 Breakout IndicatorLevel: 1
Background
A breakout refers to when the price of an asset moves above a resistance area or below a support area. Breakouts indicate that the price may be trending in the direction of the breakout.
Function
L1 Breakout Indicator utilizes highest() and lowest() functions to define breakout levels. Use ema() to draw a trade line to detect the distance to breakout points. By doing that, you will know whether is overbought or oversold. Then, by applying a set of simple threshold inputs, you can locate the long and short entries points.
Key Signal
trade line and its lag version
Pros and Cons
Pros:
1. Simple but powerful to know overbought and oversold regions
2. Flexible input threshold values to adapt various market conditions
Cons:
1. It may satruate for extreme conditions of long and short.
2. Multiple long and short entries may be generated.
Remarks
Just simple
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
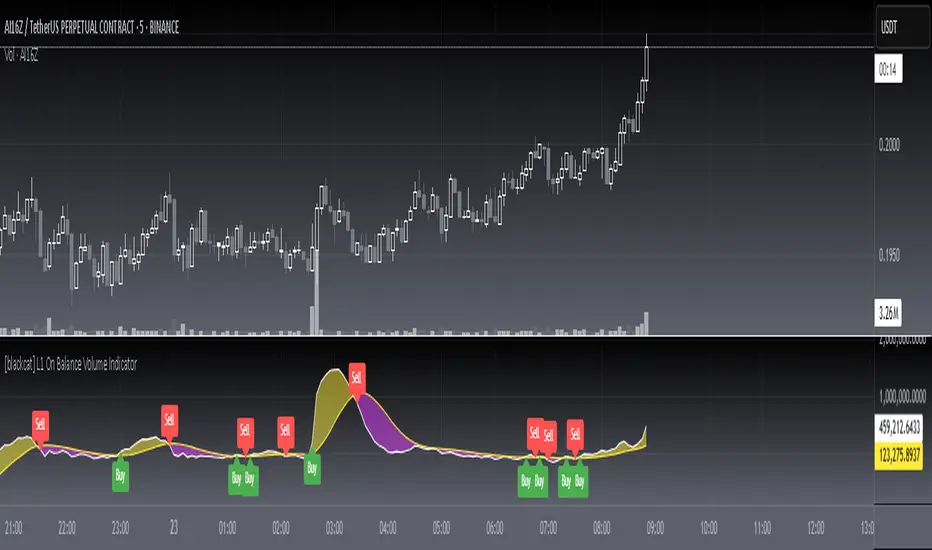
L1 On Balance Volume IndicatorLevel: 1
Background
On Balance Volume (OBV) is a simple indicator that uses volume and price to measure buying and selling pressure. The buying pressure is evident when the positive volume exceeds the negative volume and the OBV line rises.
Function
L1 On Balance Volume Indicator is a simple but improved OBV by using alma and more input parameters
Key Signal
OBV and its ALMA
Pros and Cons
Pros:
1. More freedom to tune with more input parameters
2. ALMA can make better tradeoff between response and smooth
Cons:
1. No details of volume generation can be disclosed
2. It may help to judge trend but not the short-term price movements.
Remarks
NA
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
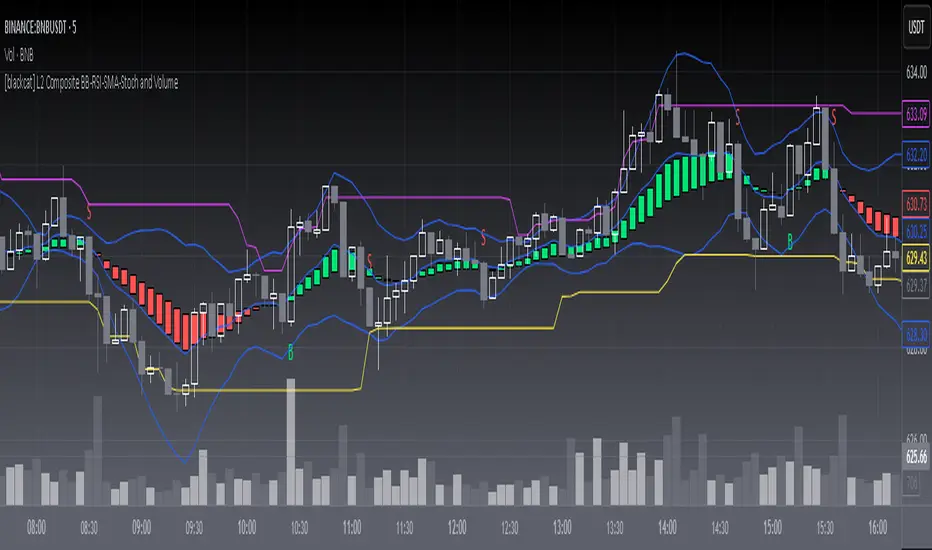
L2 Composite BB-RSI-SMA-Stoch and VolumeLevel: 2
Background
Commonly we cannot use signal indicator to disclose the nature of market. By using multiple indicator resonance, the confidence level of trading is increased. The selection of proper ingredients is important to guarantee a good results.
Function
L2 Composite BB-RSI-SMA-Stoch and Volume script likes a Pizza that you can put your favorite ingredients and condiments. In my menu, there are basic indicators as below:
Bollinger bands are envelopes with a standard deviation above and below a simple moving average of price. Since the spacing of the bands is based on the standard deviation, they adjust to the fluctuations in volatility in the underlying price.
The Relative Strength Index (RSI) developed by J. Welles Wilder is a pulse oscillator that measures the speed and change of price movements. The RSI hovers between zero and 100.
A simple moving average (SMA) is an arithmetic moving average that is calculated by adding up current prices and then dividing by the number of time periods in the calculation average.
A stochastic oscillator is a momentum indicator that compares a certain closing price of a security with a range of its prices over a certain period of time. The sensitivity to market movements can be reduced by adjusting this time period or by taking a moving average of the result.
Volume meters are the ones that make up the volume, usually an underestimated indicator.
Key Signal
Composite signal is simple and difficult to describe the overall function. By simple logic "and", "or", you can filter out the noise and disclose the real market trend.
Pros and Cons
Pros:
1. Higher confidence level for trading due to indicator resonance effect.
2. Incl. long, short, and close, three types of signal.
3. Easy to migrate and adapt to various markets.
Cons:
1. Highly emphasized on long signal, for short signal is a little bit weak.
2. Only use for trading pairs with volume information. Indice is not applicable.
3. Although I tried to use a set of "Golden Parameters", it still need to be tuned along different markets, time frame upon situations.
4. It is complex if you are wondering to introduce new indicator together with them. A lot of efforts may be needed.
Remarks
The opinions of most people in the market may not be correct, but the opinions of most indicators are closer to correct.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
Pivot Point Calculator [JP&Dia]English User Guide
Script Name: Pivot Point Calculator
What Does This Script Do? This script calculates classic and Camarilla pivot points used in financial markets. Pivot points are used to identify key support and resistance levels, and this script helps traders better understand market movements.
How to Use It?
Add the script to your charts on TradingView.
Enter your desired time frame in the “Enter Time Frame” field (e.g., M, W, D).
Choose either or both “Classic Pivot” and “Camarilla Pivot” options to display them.
The script will automatically calculate the pivot points and display them on the chart.
Why Is This Script Unique? This script combines both classic and Camarilla pivot calculations, allowing users to easily utilize both pivot styles through a single script.
How Can People Benefit? Traders can use this script to identify potential buy-sell points and market trends. They can also conduct their market analyses more efficiently and effectively.
Script Adı: Pivot Noktası Hesaplayıcı
Script Ne İşe Yarar? Bu script, finansal piyasalarda kullanılan klasik ve Camarilla pivot noktalarını hesaplar. Pivot noktaları, önemli destek ve direnç seviyelerini belirlemek için kullanılır ve bu script, yatırımcıların piyasa hareketlerini daha iyi anlamalarına yardımcı olur.
Nasıl Kullanılır?
Scripti TradingView’deki grafiklerinize ekleyin.
“Zaman Dilimi Girin” alanına istediğiniz zaman dilimini girin (Örneğin: M, W, D).
“Classic Pivot” ve “Camarilla Pivot” seçeneklerinden birini veya her ikisini de seçerek gösterilmesini sağlayabilirsiniz.
Script otomatik olarak pivot noktalarını hesaplayacak ve grafik üzerinde gösterecektir.
Neden Özgü Bir Script? Bu script, hem klasik hem de Camarilla pivot hesaplamalarını birleştirir ve kullanıcıların her iki pivot stilini de tek bir script üzerinden kolayca kullanmalarını sağlar.
İnsanlar Nasıl Faydalanabilir? Yatırımcılar, bu scripti kullanarak potansiyel alım-satım noktalarını ve piyasa trendlerini belirleyebilirler. Ayrıca, piyasa analizlerini daha verimli ve etkili bir şekilde yapabilirler.
TradingView.To Strategy Template (with Dyanmic Alerts)Hello traders,
If you're tired of manual trading and looking for a solid strategy template to pair with your indicators, look no further.
This Pine Script v5 strategy template is engineered for maximum customization and risk management.
Best part?
This Pine Script v5 template facilitates the dynamic construction of TradingView.TO alerts, sparing users the time and effort of mastering the TradingView.TO syntax and manually create alert commands.
This powerful tool gives much power to those who don't know how to code in Pinescript and want to automate their indicators' signals via TradingView.TO bot.
IMPORTANT NOTES
TradingView.TO is a trading bot software that forwards TradingView alerts to your brokers (examples: Binance, Oanda, Coinbase, Bybit, Metatrader 4/5, ...) for automating trading.
Many traders don't know how to create TradingView.TO dynamically-compatible alerts using the data from their TradingView scripts.
Traders using trading bots want their alerts to reflect the stop-loss/take-profit/trailing-stop/stop-loss to break options from your script and then create the orders accordingly.
This script showcases how to create TradingView.TO alerts dynamically.
TRADINGVIEW ALERTS
1) You'll have to create one alert per asset X timeframe = 1 chart.
Example: 1 alert for BTC/USDT on the 5 minutes chart, 1 alert for BTC/USDT on the 15-minute chart (assuming you want your bot to trade the BTC/USDT on the 5 and 15-minute timeframes)
2) Select the Order fills and alert() function calls condition
3) For each alert, the alert message is pre-configured with the text below
{{strategy.order.alert_message}}
Please leave it as it is.
It's a TradingView native variable that will fetch the alert text messages built by the script.
4) TradingView.TO uses webhook technology - setting a webhook URL from the alerts notifications tab is required.
KEY FEATURES
I) Modular Indicator Connection
* plug your existing indicator into the template.
* Only two lines of code are needed for full compatibility.
Step 1: Create your connector
Adapt your indicator with only 2 lines of code and then connect it to this strategy template.
To do so:
1) Find in your indicator where the conditions print the long/buy and short/sell signals.
2) Create an additional plot as below
I'm giving an example with a Two moving averages cross.
Please replicate the same methodology for your indicator, whether a MACD , ZigZag, Pivots , higher-highs, lower-lows or whatever indicator with clear buy and sell conditions.
//@version=5
indicator("Supertrend", overlay = true, timeframe = "", timeframe_gaps = true)
atrPeriod = input.int(10, "ATR Length", minval = 1)
factor = input.float(3.0, "Factor", minval = 0.01, step = 0.01)
= ta.supertrend(factor, atrPeriod)
supertrend := barstate.isfirst ? na : supertrend
bodyMiddle = plot(barstate.isfirst ? na : (open + close) / 2, display = display.none)
upTrend = plot(direction < 0 ? supertrend : na, "Up Trend", color = color.green, style = plot.style_linebr)
downTrend = plot(direction < 0 ? na : supertrend, "Down Trend", color = color.red, style = plot.style_linebr)
fill(bodyMiddle, upTrend, color.new(color.green, 90), fillgaps = false)
fill(bodyMiddle, downTrend, color.new(color.red, 90), fillgaps = false)
buy = ta.crossunder(direction, 0)
sell = ta.crossunder(direction, 0)
//////// CONNECTOR SECTION ////////
Signal = buy ? 1 : sell ? -1 : 0
plot(Signal, title = "Signal", display = display.data_window)
//////// CONNECTOR SECTION ////////
Important Notes
🔥 The Strategy Template expects the value to be exactly 1 for the bullish signal and -1 for the bearish signal
Now, you can connect your indicator to the Strategy Template using the method below or that one.
Step 2: Connect the connector
1) Add your updated indicator to a TradingView chart
2) Add the Strategy Template as well to the SAME chart
3) Open the Strategy Template settings, and in the Data Source field, select your 🔌Connector🔌 (which comes from your indicator)
Note it doesn’t have to be named 🔌Connector🔌 - you can name it as you want - however, I recommend an explicit name you can easily remember.
From then, you should start seeing the signals and plenty of other stuff on your chart.
🔥 Note that whenever you update your indicator values, the strategy statistics and visuals on your chart will update in real-time
II) BOT Risk Management:
- Max Drawdown:
Mode: Select whether the max drawdown is calculated in percentage (%) or USD.
Value: If the max drawdown reaches this specified value, set a value to halt the bot.
- Max Consecutive Days:
Use Max Consecutive Days BOT Halt: Enable/Disable halting the bot if the max consecutive losing days value is reached.
- Max Consecutive Days: Set the maximum number of consecutive losing days allowed before halting the bot.
- Max Losing Streak:
Use Max Losing Streak: Enable/Disable a feature to prevent the bot from taking too many losses in a row.
- Max Losing Streak Length: Set the maximum length of a losing streak allowed.
Margin Call:
- Use Margin Call: Enable/Disable a feature to exit when a specified percentage away from a margin call to prevent it.
Margin Call (%): Set the percentage value to trigger this feature.
- Close BOT Total Loss:
Use Close BOT Total Loss: Enable/Disable a feature to close all trades and halt the bot if the total loss is reached.
- Total Loss ($): Set the total loss value in USD to trigger this feature.
Intraday BOT Risk Management:
- Intraday Losses:
Use Intraday Losses BOT Halt: Enable/Disable halting the bot on reaching specified intraday losses.
Mode: Select whether the intraday loss is calculated in percentage (%) or USD.
- Max Intraday Losses (%): Set the value for maximum intraday losses.
Limit Intraday Trades:
- Use Limit Intraday Trades: Enable/Disable a feature to limit the number of intraday trades.
- Max Intraday Trades: Set the maximum number of intraday trades allowed.
Restart Intraday EA:
III) Order Types and Position Sizing
- Choose between market or limit orders.
- Set your position size directly in the template.
Please use the position size from the “Inputs” and not the “Properties” tab.
I know it's redundant. - the template needs this value from the "Inputs" tab to build the alerts, and the Backtester needs it from the "Properties" tab.
IV) Advanced Take-Profit and Stop-Loss Options
- Choose to set your SL/TP in either USD or percentages.
- Option for multiple take-profit levels and trailing stop losses.
- Move your stop loss to break even +/- offset in USD for “risk-free” trades.
V) Miscellaneous:
Retry order openings if they fail.
Order Types:
Select and specify order type and price settings.
Position Size:
Define the type and size of positions.
Leverage:
Leverage settings, including margin type and hedge mode.
Session:
Limit trades to specific sessions.
Dates:
Limit trades to a specific date range.
Trades Direction:
Direction: Specify the market direction for opening positions.
VI) Logger
The TradingView.TO commands are logged in the TradingView logger.
You'll find more information about it in this TradingView blog post .
WHY YOU MIGHT NEED THIS TEMPLATE
1) Transform your indicator into a TradingView.TO trading bot more easily than before
Connect your indicator to the template
Create your alerts
Set your EA settings
2) Save Time
Auto-generated alert messages for TradingView.TO.
I tested them all and checked with the support team what could/couldn’t be done.
3) Be in Control
Manage your trading risks with advanced features.
4) Customizable
Fits various trading styles and asset classes.
REQUIREMENTS
* Make sure you have your TradingView.TO account
* If there is any issue with the template, ask me in the comments section - I’ll answer quickly.
BACKTEST RESULTS FROM THIS POST
1) I connected this strategy template to a dummy Supertrend script.
I could have selected any other indicator or concept for this script post.
I wanted to share an example of how you can quickly upgrade your strategy, making it compatible with TradingView.TO.
2) The backtest results aren't relevant for this educational script publication.
I used realistic backtesting data but didn't look too much into optimizing the results, as this isn't the point of why I'm publishing this script.
This strategy is a template to be connected to any indicator - the sky is the limit. :)
3) This template is made to take 1 trade per direction at any given time.
Pyramiding is set to 1 on TradingView.
The strategy default settings are:
* Initial Capital: 100000 USD
* Position Size: 1%
* Commission Percent: 0.075%
* Slippage: 1 tick
* No margin/leverage used

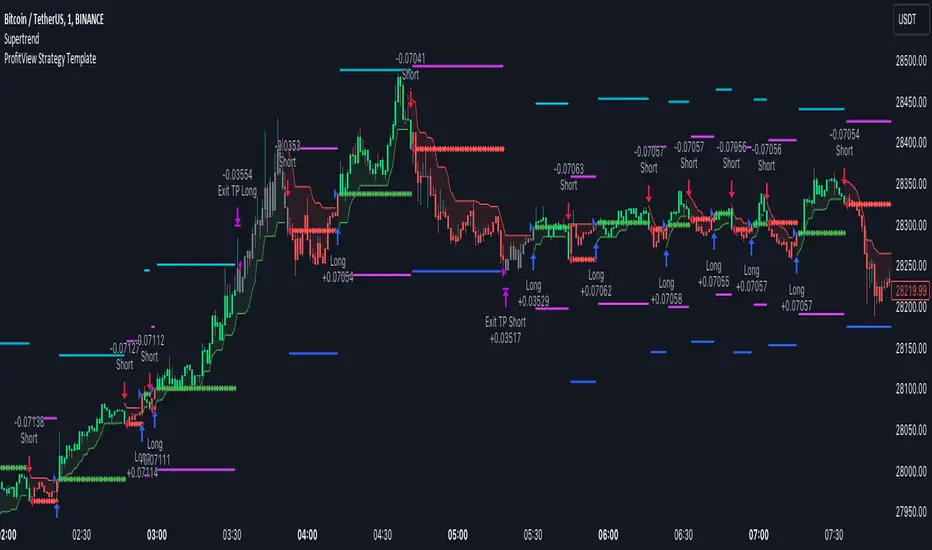
ProfitView Strategy TemplateHello traders,
This script took me a full week of coding/testing, sweat, and tears - and I’m too nice as I’m giving it for free to the community.
If you're tired of manual trading and looking for a solid strategy template to pair with your indicators, look no further.
This Pine Script v5 strategy template is engineered for maximum customization and risk management.
Best part?
This Pine Script v5 template facilitates the dynamic construction of ProfitView alerts, sparing users the time and effort of mastering the ProfitView syntax and manually creating alert commands.
This powerful tool gives much power to those who don't know how to code in Pinescript and want to automate their indicators' signals via the ProfitView Chrome extension.
IMPORTANT NOTES
ProfitView is a trading bot software that forwards TradingView alerts to your brokers (examples: Binance, Oanda, Coinbase, Bybit, etc.) for automating trading.
Many traders don't know how to dynamically create ProfitView-compatible alerts using the data from their TradingView scripts.
Traders using trading bots want their alerts to reflect the stop-loss/take-profit/trailing-stop/stop-loss to break options from your script and then create the orders accordingly.
This script showcases how to create ProfitView alerts dynamically.
TRADINGVIEW ALERTS
1) You'll have to create one alert per asset X timeframe = 1 chart.
Example: 1 alert for EUR/USD on the 5 minutes chart, 1 alert for EUR/USD on the 15-minute chart (assuming you want your bot to trade the EUR/USD on the 5 and 15-minute timeframes)
2) Select the Order fills and alert() function calls condition
3) For each alert, the alert message is pre-configured with the text below
{{strategy.order.alert_message}}
Please leave it as it is.
It's a TradingView native variable that will fetch the alert text messages built by the script.
4) ProfitView doesn't use webhook technology, so setting a webhook URL from the alerts notifications tab is unnecessary.
KEY FEATURES
I) Modular Indicator Connection
* plug your existing indicator into the template.
* Only two lines of code are needed for full compatibility.
Step 1: Create your connector
Adapt your indicator with only 2 lines of code and then connect it to this strategy template.
To do so:
1) Find in your indicator where the conditions print the long/buy and short/sell signals.
2) Create an additional plot as below
I'm giving an example with a Two moving averages cross.
Please replicate the same methodology for your indicator, whether a MACD , ZigZag, Pivots , higher-highs, lower-lows or whatever indicator with clear buy and sell conditions.
//@version=5
indicator("Supertrend", overlay = true, timeframe = "", timeframe_gaps = true)
atrPeriod = input.int(10, "ATR Length", minval = 1)
factor = input.float(3.0, "Factor", minval = 0.01, step = 0.01)
= ta.supertrend(factor, atrPeriod)
supertrend := barstate.isfirst ? na : supertrend
bodyMiddle = plot(barstate.isfirst ? na : (open + close) / 2, display = display.none)
upTrend = plot(direction < 0 ? supertrend : na, "Up Trend", color = color.green, style = plot.style_linebr)
downTrend = plot(direction < 0 ? na : supertrend, "Down Trend", color = color.red, style = plot.style_linebr)
fill(bodyMiddle, upTrend, color.new(color.green, 90), fillgaps = false)
fill(bodyMiddle, downTrend, color.new(color.red, 90), fillgaps = false)
buy = ta.crossunder(direction, 0)
sell = ta.crossunder(direction, 0)
//////// CONNECTOR SECTION ////////
Signal = buy ? 1 : sell ? -1 : 0
plot(Signal, title = "Signal", display = display.data_window)
//////// CONNECTOR SECTION ////////
Important Notes
🔥 The Strategy Template expects the value to be exactly 1 for the bullish signal and -1 for the bearish signal
Now, you can connect your indicator to the Strategy Template using the method below or that one.
Step 2: Connect the connector
1) Add your updated indicator to a TradingView chart
2) Add the Strategy Template as well to the SAME chart
3) Open the Strategy Template settings, and in the Data Source field, select your 🔌Connector🔌 (which comes from your indicator)
Note it doesn’t have to be named 🔌Connector🔌 - you can name it as you want - however, I recommend an explicit name you can easily remember.
From then, you should start seeing the signals and plenty of other stuff on your chart.
🔥 Note that whenever you update your indicator values, the strategy statistics and visuals on your chart will update in real-time
II) BOT Risk Management:
- Max Drawdown:
Mode: Select whether the max drawdown is calculated in percentage (%) or USD.
Value: If the max drawdown reaches this specified value, set a value to halt the bot.
- Max Consecutive Days:
Use Max Consecutive Days BOT Halt: Enable/Disable halting the bot if the max consecutive losing days value is reached.
- Max Consecutive Days: Set the maximum number of consecutive losing days allowed before halting the bot.
- Max Losing Streak:
Use Max Losing Streak: Enable/Disable a feature to prevent the bot from taking too many losses in a row.
- Max Losing Streak Length: Set the maximum length of a losing streak allowed.
Margin Call:
- Use Margin Call: Enable/Disable a feature to exit when a specified percentage away from a margin call to prevent it.
Margin Call (%): Set the percentage value to trigger this feature.
- Close BOT Total Loss:
Use Close BOT Total Loss: Enable/Disable a feature to close all trades and halt the bot if the total loss is reached.
- Total Loss ($): Set the total loss value in USD to trigger this feature.
Intraday BOT Risk Management:
- Intraday Losses:
Use Intraday Losses BOT Halt: Enable/Disable halting the bot on reaching specified intraday losses.
Mode: Select whether the intraday loss is calculated in percentage (%) or USD.
- Max Intraday Losses (%): Set the value for maximum intraday losses.
Limit Intraday Trades:
- Use Limit Intraday Trades: Enable/Disable a feature to limit the number of intraday trades.
- Max Intraday Trades: Set the maximum number of intraday trades allowed.
Restart Intraday EA:
- Use Restart Intraday EA: Enable/Disable a feature to restart the bot at the first bar of the next day if it has been stopped with an intraday risk management safeguard.
III) Order Types and Position Sizing
- Choose between market, limit, or stop orders.
- Set your position size directly in the template.
Please use the position size from the “Inputs” and not the “Properties” tab.
I know it's redundant. - the template needs this value from the "Inputs" tab to build the alerts, and the Backtester needs it from the "Properties" tab.
IV) Advanced Take-Profit and Stop-Loss Options
- Choose to set your SL/TP in either pips or percentages.
- Option for multiple take-profit levels and trailing stop losses.
- Move your stop loss to break even +/- offset in pips for “risk-free” trades.
V) Miscellaneous
Retry order openings if they fail.
Order Types:
Select and specify order type and price settings.
Position Size:
Define the type and size of positions.
Leverage:
Leverage settings, including margin type and hedge mode.
Session:
Limit trades to specific sessions.
Dates:
Limit trades to a specific date range.
Trades Direction:
Direction: Specify the market direction for opening positions.
VI) Notifications (Telegram/Discord/Email/IFTTT/Twilio/SMS)
Customize notifications sent to Telegram, Discord, Email, IFTTT, Twilio, and ProfitView Logger.
VII) Logger
The ProfitView commands are logged in the TradingView logger.
You'll find more information about it in this TradingView blog post .
WHY YOU MIGHT NEED THIS TEMPLATE
1) Transform your indicator into a ProfitView trading bot more easily than before
Connect your indicator to the template
Create your alerts
Set your EA settings
2) Save Time
Auto-generated alert messages for ProfitView.
I tested them all and checked with the support team what could/couldn’t be done.
3) Be in Control
Manage your trading risks with advanced features.
4) Customizable
Fits various trading styles and asset classes.
REQUIREMENTS
* Make sure you have your ProfitView account and do the settings correctly in your Chrome extension. If you don't know how to do it, read the documentation + ask for help in the ProfitView Discord support channel.
* If there is any issue with the template, ask me in the comments section - I’ll answer quickly.
BACKTEST RESULTS FROM THIS POST
1) I connected this strategy template to a dummy Supertrend script.
I could have selected any other indicator or concept for this script post.
I wanted to share an example of how you can quickly upgrade your strategy, making it compatible with ProfitView.
2) The backtest results aren't relevant for this educational script publication.
I used realistic backtesting data but didn't look too much into optimizing the results, as this isn't the point of why I'm publishing this script.
This strategy is a template to be connected to any indicator - the sky is the limit. :)
3) This template is made to take 1 trade per direction at any given time.
Pyramiding is set to 1 on TradingView.
The strategy default settings are:
* Initial Capital: 100000 USD
* Position Size: 1%
* Commission Percent: 0.075%
* Slippage: 1 tick
* No margin/leverage used
Best regards,
Dave
Pineconnector Strategy Template (Connect Any Indicator)Hello traders,
If you're tired of manual trading and looking for a solid strategy template to pair with your indicators, look no further.
This Pine Script v5 strategy template is engineered for maximum customization and risk management.
Best part?
It’s optimized for Pineconnector, allowing seamless integration with MetaTrader 4 and 5.
This powerful tool gives a lot of power to those who don't know how to code in Pinescript and are looking to automate their indicators' signals on Metatrader 4/5.
IMPORTANT NOTES
Pineconnector is a trading bot software that forwards TradingView alerts to your Metatrader 4/5 for automating trading.
Many traders don't know how to dynamically create Pineconnector-compatible alerts using the data from their TradingView scripts.
Traders using trading bots want their alerts to reflect the stop-loss/take-profit/trailing-stop/stop-loss to break options from your script and then create the orders accordingly.
This script showcases how to create Pineconnector alerts dynamically.
Pineconnector doesn't support alerts with multiple Take Profits.
As a workaround, for 2 TPs, I had to open two trades.
It's not optimal, as we end up paying more spreads for that extra trade - however, depending on your trading strategy, it may not be a big deal.
TRADINGVIEW ALERTS
1) You'll have to create one alert per asset X timeframe = 1 chart.
Example: 1 alert for EUR/USD on the 5 minutes chart, 1 alert for EUR/USD on the 15-minute chart (assuming you want your bot to trade the EUR/USD on the 5 and 15-minute timeframes)
2) Select the Order fills and alert() function calls condition
3) For each alert, the alert message is pre-configured with the text below
{{strategy.order.alert_message}}
Please leave it as it is.
It's a TradingView native variable that will fetch the alert text messages built by the script.
4) Don't forget to set the Pineconnector webhook URL in the Notifications tab of the TradingView alerts UI.
You’ll find the URL on the Pineconnector documentation website.
EA CONFIGURATION
1) The Pyramiding in the EA on Metatrader must be set to 2 if you want to trade with 2 TPs => as it's opening 2 trades.
If you only want 1 TP, set the EA Pyramiding to 1.
Regarding the other EA settings, please refer to the Pineconnector documentation on their website.
2) In the EA, you can set a risk (= position size type) in %/lots/USD, as in the TradingView backtest settings.
KEY FEATURES
I) Modular Indicator Connection
* plug in your existing indicator into the template.
* Only two lines of code are needed for full compatibility.
Step 1: Create your connector
Adapt your indicator with only 2 lines of code and then connect it to this strategy template.
To do so:
1) Find in your indicator where the conditions print the long/buy and short/sell signals.
2) Create an additional plot as below
I'm giving an example with a Two moving averages cross.
Please replicate the same methodology for your indicator, whether it's a MACD , ZigZag , Pivots , higher-highs, lower-lows, or whatever indicator with clear buy and sell conditions.
//@version=5
indicator("Supertrend", overlay = true, timeframe = "", timeframe_gaps = true)
atrPeriod = input.int(10, "ATR Length", minval = 1)
factor = input.float(3.0, "Factor", minval = 0.01, step = 0.01)
= ta.supertrend(factor, atrPeriod)
supertrend := barstate.isfirst ? na : supertrend
bodyMiddle = plot(barstate.isfirst ? na : (open + close) / 2, display = display.none)
upTrend = plot(direction < 0 ? supertrend : na, "Up Trend", color = color.green, style = plot.style_linebr)
downTrend = plot(direction < 0 ? na : supertrend, "Down Trend", color = color.red, style = plot.style_linebr)
fill(bodyMiddle, upTrend, color.new(color.green, 90), fillgaps = false)
fill(bodyMiddle, downTrend, color.new(color.red, 90), fillgaps = false)
buy = ta.crossunder(direction, 0)
sell = ta.crossunder(direction, 0)
//////// CONNECTOR SECTION ////////
Signal = buy ? 1 : sell ? -1 : 0
plot(Signal, title = "Signal", display = display.data_window)
//////// CONNECTOR SECTION ////////
Important Notes
🔥 The Strategy Template expects the value to be exactly 1 for the bullish signal and -1 for the bearish signal
Now, you can connect your indicator to the Strategy Template using the method below or that one.
Step 2: Connect the connector
1) Add your updated indicator to a TradingView chart
2) Add the Strategy Template as well to the SAME chart
3) Open the Strategy Template settings, and in the Data Source field, select your 🔌Connector🔌 (which comes from your indicator)
Note it doesn’t have to be named 🔌Connector🔌 - you can name it as you want - however, I recommend an explicit name you can easily remember.
From then, you should start seeing the signals and plenty of other stuff on your chart.
🔥 Note that whenever you update your indicator values, the strategy statistics and visuals on your chart will update in real-time
II) Customizable Risk Management
- Choose between percentage or USD modes for maximum drawdown.
- Set max consecutive losing days and max losing streak length.
- I used the code from my friend @JosKodify for the maximum losing streak. :)
Will halt the EA and backtest orders fill whenever either of the safeguards above are “broken”
III) Intraday Risk Management
- Limit the maximum intraday losses both in percentage or USD.
- Option to set a maximum number of intraday trades.
- If your EA gets halted on an intraday chart, auto-restart it the next day.
IV) Spread and Account Filters
- Trade only if the spread is below a certain pip value.
- Set requirements based on account balance or equity.
V) Order Types and Position Sizing
- Choose between market, limit, or stop orders.
- Set your position size directly in the template.
Please use the position size from the “Inputs” and not the “Properties” tab.
Reason : The template sends the order on the same candle as the entry signals - at those entry signals candles, the position size isn’t computed yet, and the template can’t then send it to Pineconnector.
However, you can use the position size type (USD, contracts, %) from the “Properties” tab for backtesting.
In the EA, you can define the position size type for your orders in USD or lots or %.
VI) Advanced Take-Profit and Stop-Loss Options
- Choose to set your SL/TP in either pips or percentages.
- Option for multiple take-profit levels and trailing stop losses.
- Move your stop loss to break even +/- offset in pips for “risk-free” trades.
VII) Logger
The Pineconnector commands are logged in the TradingView logger.
You'll find more information about it in this TradingView blog post .
WHY YOU MIGHT NEED THIS TEMPLATE
1) Transform your indicator into a Pineconnector trading bot more easily than before
Connect your indicator to the template
Create your alerts
Set your EA settings
2) Save Time
Auto-generated alert messages for Pineconnector.
I tested them all, and I checked with the support team what could/can’t be done
3) Be in Control
Manage your trading risks with advanced features.
4) Customizable
Fits various trading styles and asset classes.
REQUIREMENTS
* Make sure you have your Pineconnector license ID.
* Create your alerts with the Pineconnector webhook URL
* If there is any issue with the template, ask me in the comments section - I’ll answer quickly.
BACKTEST RESULTS FROM THIS POST
1) I connected this strategy template to a dummy Supertrend script.
I could have selected any other indicator or concept for this script post.
I wanted to share an example of how you can quickly upgrade your strategy, making it compatible with Pineconnector.
2) The backtest results aren't relevant for this educational script publication.
I used realistic backtesting data but didn't look too much into optimizing the results, as this isn't the point of why I'm publishing this script.
This strategy is a template to be connected to any indicator - the sky is the limit. :)
3) This template is made to take 1 trade per direction at any given time.
Pyramiding is set to 1 on TradingView.
The strategy default settings are:
* Initial Capital: 100000 USD
* Position Size: 1 contract
* Commission Percent: 0.075%
* Slippage: 1 tick
* No margin/leverage used
WHAT’S COMING NEXT FOR YOU GUYS?
I’ll make the same template for ProfitView, then for AutoView, and then for Alertatron.
All of those are free and open-source.
I have no affiliations with any of those companies - I'm publishing those templates as they will be useful to many of you.
Dave

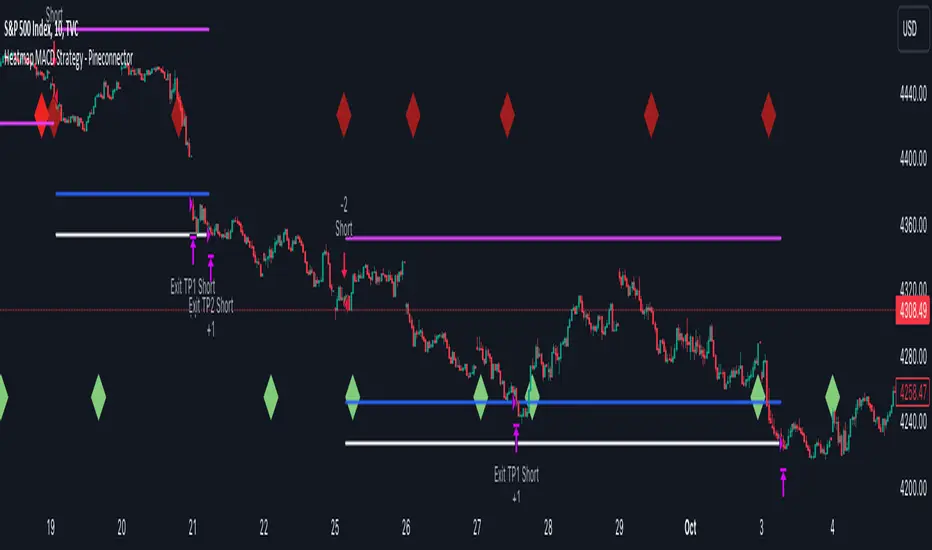
Heatmap MACD Strategy - Pineconnector (Dynamic Alerts)Hello traders
This script is an upgrade of this template script.
Heatmap MACD Strategy
Pineconnector
Pineconnector is a trading bot software that forwards TradingView alerts to your Metatrader 4/5 for automating trading.
Many traders don't know how to dynamically create Pineconnector-compatible alerts using the data from their TradingView scripts.
Traders using trading bots want their alerts to reflect the stop-loss/take-profit/trailing-stop/stop-loss to breakeven options from your script and then create the orders accordingly.
This script showcases how to create Pineconnector alerts dynamically.
Pineconnector doesn't support alerts with multiple Take Profits.
As a workaround, for 2 TPs, I had to open two trades.
It's not optimal, as we end up paying more spreads for that extra trade - however, depending on your trading strategy, it may not be a big deal.
TradingView Alerts
1) You'll have to create one alert per asset X timeframe = 1 chart.
Example : 1 alert for EUR/USD on the 5 minutes chart, 1 alert for EUR/USD on the 15-minute chart (assuming you want your bot to trade the EUR/USD on the 5 and 15-minute timeframes)
2) For each alert, the alert message is pre-configured with the text below
{{strategy.order.alert_message}}
Please leave it as it is.
It's a TradingView native variable that will fetch the alert text messages built by the script.
3) Don't forget to set the webhook URL in the Notifications tab of the TradingView alerts UI.
EA configuration
The Pyramiding in the EA on Metatrader must be set to 2 if you want to trade with 2 TPs => as it's opening 2 trades.
If you only want 1 TP, set the EA Pyramiding to 1.
Regarding the other EA settings, please refer to the Pineconnector documentation on their website.
Logger
The Pineconnector commands are logged in the TradingView logger.
You'll find more information about it from this TradingView blog post
Important Notes
1) This multiple MACDs strategy doesn't matter much.
I could have selected any other indicator or concept for this script post.
I wanted to share an example of how you can quickly upgrade your strategy, making it compatible with Pineconnector.
2) The backtest results aren't relevant for this educational script publication.
I used realistic backtesting data but didn't look too much into optimizing the results, as this isn't the point of why I'm publishing this script.
3) This template is made to take 1 trade per direction at any given time.
Pyramiding is set to 1 on TradingView.
The strategy default settings are:
Initial Capital: 100000 USD
Position Size: 1 contract
Commission Percent: 0.075%
Slippage: 1 tick
No margin/leverage used
For example, those are realistic settings for trading CFD indices with low timeframes but not the best possible settings for all assets/timeframes.
Concept
The Heatmap MACD Strategy allows selecting one MACD in five different timeframes.
You'll get an exit signal whenever one of the 5 MACDs changes direction.
Then, the strategy re-enters whenever all the MACDs are in the same direction again.
It takes:
long trades when all the 5 MACD histograms are bullish
short trades when all the 5 MACD histograms are bearish
You can select the same timeframe multiple times if you don't need five timeframes.
For example, if you only need the 30min, the 1H, and 2H, you can set your timeframes as follow:
30m
30m
30m
1H
2H
Risk Management Features
All the features below are pips-based.
Stop-Loss
Trailing Stop-Loss
Stop-Loss to Breakeven after a certain amount of pips has been reached
Take Profit 1st level and closing X% of the trade
Take Profit 2nd level and close the remaining of the trade
Custom Exit
I added the option ON/OFF to close the opened trade whenever one of the MACD diverges with the others.
Help me help the community
If you see any issue when adding your strategy logic to that template regarding the orders fills on your Metatrader, please let me know in the comments.
I'll use your feedback to make this template more robust. :)
What's next?
I'll publish a more generic template built as a connector so you can connect any indicator to that Pineconnector template.
Then, I'll publish a template for Capitalise AI, ProfitView, AutoView, and Alertatron.
Thank you
Dave
WWV_LB pivotfix histogram jayy
This is a modification of LazyBear's WWV_LB which plots cumulative volume of waves. The reversal points are defined through relative closing prices. I made adjustments to the script to show waves turning on actual/true low or high pivots as opposed to the bar/candle identified in the LazyBear script. What I mean by that is that the actual/true low or high pivots are in fact the true WWV_LB pivots. The original WWV_LB script calculates cumulative volume from reversal confirmation bar to reversal confirmation bar as opposed to the true WWV_LB pivot bar to pivot bar. As such the waves can have slightly different start and end points. As such the cumulative volume can also be different from te WWV_LB script. This is because confirmation of a wave reversal can lag a few bars after the true reversal pivot bar. In the script notes, you will see the original key WWV_LB script lines that identify the true high or low pivots and confirm the wave direction has reversed. I have taken these lines from LazyBear's original script. I have included the LazyBear script within the script notes so that the original can be compared to what I have added/changed. Instead of "trendDetectionLength" I have inserted "Trend Detection Length". You can of course change the descriptor to what you wish by editing script line 33 to the original term or whatever you wish. You might also wish to set the default to the value "2" as per the original script. I have set the default to "3". This script should be used in conjunction with "WWV-LB zigzag pivot fix jayy" script which is shown on this screen for comparison.
Here is a link to the original LazyBear histogram script which can be used for comparison. The differences are subtle, however, the histograms will regularly be different by a bar or two:
The lowest panel has the original LazyBear WWV_LB script for comparison. All three scripts have been set to a Trend Detection Length of 3.jayy

Ensemble Alerts█ OVERVIEW
This indicator creates highly customizable alert conditions and messages by combining several technical conditions into groups , which users can specify directly from the "Settings/Inputs" tab. It offers a flexible framework for building and testing complex alert conditions without requiring code modifications for each adjustment.
█ CONCEPTS
Ensemble analysis
Ensemble analysis is a form of data analysis that combines several "weaker" models to produce a potentially more robust model. In a trading context, one of the most prevalent forms of ensemble analysis is the aggregation (grouping) of several indicators to derive market insights and reinforce trading decisions. With this analysis, traders typically inspect multiple indicators, signaling trade actions when specific conditions or groups of conditions align.
Simplifying ensemble creation
Combining indicators into one or more ensembles can be challenging, especially for users without programming knowledge. It usually involves writing custom scripts to aggregate the indicators and trigger trading alerts based on the confluence of specific conditions. Making such scripts customizable via inputs poses an additional challenge, as it often involves complicated input menus and conditional logic.
This indicator addresses these challenges by providing a simple, flexible input menu where users can easily define alert criteria by listing groups of conditions from various technical indicators in simple text boxes . With this script, you can create complex alert conditions intuitively from the "Settings/Inputs" tab without ever writing or modifying a single line of code. This framework makes advanced alert setups more accessible to non-coders. Additionally, it can help Pine programmers save time and effort when testing various condition combinations.
█ FEATURES
Configurable alert direction
The "Direction" dropdown at the top of the "Settings/Inputs" tab specifies the allowed direction for the alert conditions. There are four possible options:
• Up only : The indicator only evaluates upward conditions.
• Down only : The indicator only evaluates downward conditions.
• Up and down (default): The indicator evaluates upward and downward conditions, creating alert triggers for both.
• Alternating : The indicator prevents alert triggers for consecutive conditions in the same direction. An upward condition must be the first occurrence after a downward condition to trigger an alert, and vice versa for downward conditions.
Flexible condition groups
This script features six text inputs where users can define distinct condition groups (ensembles) for their alerts. An alert trigger occurs if all the conditions in at least one group occur.
Each input accepts a comma-separated list of numbers with optional spaces (e.g., "1, 4, 8"). Each listed number, from 1 to 35, corresponds to a specific individual condition. Below are the conditions that the numbers represent:
1 — RSI above/below threshold
2 — RSI below/above threshold
3 — Stoch above/below threshold
4 — Stoch below/above threshold
5 — Stoch K over/under D
6 — Stoch K under/over D
7 — AO above/below threshold
8 — AO below/above threshold
9 — AO rising/falling
10 — AO falling/rising
11 — Supertrend up/down
12 — Supertrend down/up
13 — Close above/below MA
14 — Close below/above MA
15 — Close above/below open
16 — Close below/above open
17 — Close increase/decrease
18 — Close decrease/increase
19 — Close near Donchian top/bottom (Close > (Mid + HH) / 2)
20 — Close near Donchian bottom/top (Close < (Mid + LL) / 2)
21 — New Donchian high/low
22 — New Donchian low/high
23 — Rising volume
24 — Falling volume
25 — Volume above average (Volume > SMA(Volume, 20))
26 — Volume below average (Volume < SMA(Volume, 20))
27 — High body to range ratio (Abs(Close - Open) / (High - Low) > 0.5)
28 — Low body to range ratio (Abs(Close - Open) / (High - Low) < 0.5)
29 — High relative volatility (ATR(7) > ATR(40))
30 — Low relative volatility (ATR(7) < ATR(40))
31 — External condition 1
32 — External condition 2
33 — External condition 3
34 — External condition 4
35 — External condition 5
These constituent conditions fall into three distinct categories:
• Directional pairs : The numbers 1-22 correspond to pairs of opposing upward and downward conditions. For example, if one of the inputs includes "1" in the comma-separated list, that group uses the "RSI above/below threshold" condition pair. In this case, the RSI must be above a high threshold for the group to trigger an upward alert, and the RSI must be below a defined low threshold to trigger a downward alert.
• Non-directional filters : The numbers 23-30 correspond to conditions that do not represent directional information. These conditions act as filters for both upward and downward alerts. Traders often use non-directional conditions to refine trending or mean reversion signals. For instance, if one of the input lists includes "30", that group uses the "Low relative volatility" condition. The group can trigger an upward or downward alert only if the 7-period Average True Range (ATR) is below the 40-period ATR.
• External conditions : The numbers 31-35 correspond to external conditions based on the plots from other indicators on the chart. To set these conditions, use the source inputs in the "External conditions" section near the bottom of the "Settings/Inputs" tab. The external value can represent an upward, downward, or non-directional condition based on the following logic:
▫ Any value above 0 represents an upward condition.
▫ Any value below 0 represents a downward condition.
▫ If the checkbox next to the source input is selected, the condition becomes non-directional . Any group that uses the condition can trigger upward or downward alerts only if the source value is not 0.
To learn more about using plotted values from other indicators, see this article in our Help Center and the Source input section of our Pine Script™ User Manual.
Group markers
Each comma-separated list represents a distinct group , where all the listed conditions must occur to trigger an alert. This script assigns preset markers (names) to each condition group to make the active ensembles easily identifiable in the generated alert messages and labels. The markers assigned to each group use the format "M", where "M" is short for "Marker" and "x" is the group number. The titles of the inputs at the top of the "Settings/Inputs" tab show these markers for convenience.
For upward conditions, the labels and alert messages show group markers with upward triangles (e.g., "M1▲"). For downward conditions, they show markers with downward triangles (e.g., "M1▼").
NOTE: By default, this script populates the "M1" field with a pre-configured list for a mean reversion group ("2,18,24,28"). The other fields are empty. If any "M*" input does not contain a value, the indicator ignores it in the alert calculations.
Custom alert messages
By default, the indicator's alert message text contains the activated markers and their direction as a comma-separated list. Users can override this message for upward or downward alerts with the two text fields at the bottom of the "Settings/Inputs" tab. When the fields are not empty , the alerts use that text instead of the default marker list.
NOTE: This script generates alert triggers, not the alerts themselves. To set up an alert based on this script's conditions, open the "Create Alert" dialog box, then select the "Ensemble Alerts" and "Any alert() function call" options in the "Condition" tabs. See the Alerts FAQ in our Pine Script™ User Manual for more information.
Condition visualization
This script offers organized visualizations of its conditions, allowing users to inspect the behaviors of each condition alongside the specified groups. The key visual features include:
1) Conditional plots
• The indicator plots the history of each individual condition, excluding the external conditions, as circles at different levels. Opposite conditions appear at positive and negative levels with the same absolute value. The plots for each condition show values only on the bars where they occur.
• Each condition's plot is color-coded based on its type. Aqua and orange plots represent opposing directional conditions, and purple plots represent non-directional conditions. The titles of the plots also contain the condition numbers to which they apply.
• The plots in the separate pane can be turned on or off with the "Show plots in pane" checkbox near the top of the "Settings/Inputs" tab. This input only toggles the color-coded circles, which reduces the graphical load. If you deactivate these visuals, you can still inspect each condition from the script's status line and the Data Window.
• As a bonus, the indicator includes "Up alert" and "Down alert" plots in the Data Window, representing the combined upward and downward ensemble alert conditions. These plots are also usable in additional indicator-on-indicator calculations.
2) Dynamic labels
• The indicator draws a label on the main chart pane displaying the activated group markers (e.g., "M1▲") each time an alert condition occurs.
• The labels for upward alerts appear below chart bars. The labels for downward alerts appear above the bars.
NOTE: This indicator can display up to 500 labels because that is the maximum allowed for a single Pine script.
3) Background highlighting
• The indicator can highlight the main chart's background on bars where upward or downward condition groups activate. Use the "Highlight background" inputs in the "Settings/Inputs" tab to enable these highlights and customize their colors.
• Unlike the dynamic labels, these background highlights are available for all chart bars, irrespective of the number of condition occurrences.
█ NOTES
• This script uses Pine Script™ v6, the latest version of TradingView's programming language. See the Release notes and Migration guide to learn what's new in v6 and how to convert your scripts to this version.
• This script imports our new Alerts library, which features functions that provide high-level simplicity for working with complex compound conditions and alerts. We used the library's `compoundAlertMessage()` function in this indicator. It evaluates items from "bool" arrays in groups specified by an array of strings containing comma-separated index lists , returning a tuple of "string" values containing the marker of each activated group.
• The script imports the latest version of the ta library to calculate several technical indicators not included in the built-in `ta.*` namespace, including Double Exponential Moving Average (DEMA), Triple Exponential Moving Average (TEMA), Fractal Adaptive Moving Average (FRAMA), Tilson T3, Awesome Oscillator (AO), Full Stochastic (%K and %D), SuperTrend, and Donchian Channels.
• The script uses the `force_overlay` parameter in the label.new() and bgcolor() calls to display the drawings and background colors in the main chart pane.
• The plots and hlines use the available `display.*` constants to determine whether the visuals appear in the separate pane.
Look first. Then leap.

Magic Touch Line DetectorSummary of the Magic Touch Line Detector Script:
Purpose:
The Magic Touch Line Detector script is designed to identify significant price points in the market by analyzing candlestick wicks and bodies. It plots lines based on the detected wicks, classifying them as either ascending or descending. The script tracks how frequently price touches these lines and highlights the "most touched" lines for both ascending and descending categories. This script is particularly useful for traders looking to identify key price levels and trends over time.
How It Works:
Wick and Body Detection:
The script starts by analyzing the highs and lows of candlestick wicks relative to their bodies over a user-defined lookback period. A significant wick is identified based on a specified wick-to-body ratio and a deviation threshold measured against the Average True Range (ATR).
Line Creation:
Once a significant upper or lower wick is detected, the script calculates unconventional highs and lows (i.e., points that differ from the absolute highs and lows of the lookback period). Lines are then drawn from these unconventional price points using the slope between the detected wick and the current bar, ensuring a smooth extension.
Line Refinement and Touch Tracking:
As new bars are added, the script tracks how often the price touches the previously drawn lines. The number of touches each line receives is counted and updated in real-time, and the script ensures that only the most touched line is highlighted.
Highlighting and Labeling:
For each category (ascending and descending), the most touched line is identified and given special highlighting with thicker lines and different colors. Labels are also generated to show the number of touches that the most touched line has received. Old labels are cleared to avoid clutter.
Explanation of the Settings:
Lookback Period for Highs and Lows:
This sets the number of bars the script will use to detect the highest highs and lowest lows. A larger lookback period gives the script a broader context to work with, potentially identifying more significant price points.
Minimum Wick-to-Body Ratio:
This ratio determines what qualifies as a "significant" wick. It compares the length of the wick to the body of the candle. A higher ratio means that only wicks that are much longer than the candle body will be considered significant.
Price Deviation Threshold (in ATR multiples):
This setting controls how much price deviation from the ATR is required for a wick to be deemed significant. It acts as a filter to reduce noise by ignoring smaller wicks that are within normal price movements.
Line Touch Tolerance Factor (ATR multiple):
When checking if a price touches a line, the script uses this setting to define how close the price must be to the line to count as a "touch." This tolerance is a multiplier of the ATR, allowing for some flexibility in what is considered a touch.
Price Difference Threshold:
This defines the minimum price difference required to plot a line. If the price difference between the high and low of a detected wick is too small, the script can avoid plotting a line for insignificant moves.
Slope Adjustment Multiplier:
This multiplier adjusts the slope of the lines that are drawn from detected price points. It affects the length and angle of the lines, allowing users to control how far and at what angle the lines should extend across the chart.
Customization Options:
Show Ascending/Descending Lines:
These toggles allow users to decide whether ascending (bullish) or descending (bearish) lines should be shown on the chart.
Line Color, Style, and Width (for Ascending and Descending Lines):
These settings give users control over how the lines appear visually. You can customize the color, style (solid, dashed, dotted), and width of both ascending and descending lines.
Most Touched Line Color:
Users can define a different color for the "most touched" line, which is automatically identified by the script. This setting helps highlight the line that has been interacted with the most by the price.
How to Use the Script:
Setup the Lookback Period and Deviation Filters:
Start by setting the lookback period and the filters for wick-to-body ratio and deviation threshold. These settings help control the script's sensitivity to market movements.
Refine the Tolerance and Slope:
Adjust the line touch tolerance and slope adjustment multiplier to control how closely the script tracks price touches and how the lines are extended on the chart.
Customize Visuals:
Once the lines are being drawn, customize the colors, styles, and widths to ensure the lines are easy to read on your chart. You can also decide if you want to display both ascending and descending lines or focus on just one.
By setting up the script based on these inputs and parameters, you can get a real-time view of significant price levels and how often the price interacts with them, helping you make more informed trading decisions.

Realtime Divergence for Any Indicator - By John BartleThe main purpose of this script is to show historical and real-time divergences for any oscillating indicator. The secondary purpose is to give the user a lot of precise control over identifying divergences and determining what they are. This is an improved version of my other script which is similarly called "Realtime Divergence for Any Indicator"
There are four types of divergences that are offered:
Bull divergence
Hidden bull divergence
Bear divergence
Hidden Bear divergence
There are three types of potential(real-time) divergences which include:
1) Without right side bars for rightside pivots. Plus without waiting for the rightside pivot bar to complete
2) Without right side bars for rightside pivots. Plus with waiting for the rightside pivot bar to complete
3) With right side bars for rightside pivots. Plus without waiting for the rightside pivot right-most bar to complete
A definite divergence occurs when all specified bars are accounted for and fully formed.
Potential divergences use dashed lines and definite(historical) divergences use solid lines.
In addition to several other categories of settings to filter out unwanted divergences or manipulate the search process, this script also offers Alerts. Remember that alerts must not only be set within this scripts settings but also your "Alerts" panel on your right. It's strange but BOTH must be set for alerts to work...
Other interesting Things To Know:
1)I actually don't trade and so I have no need of a paid account. Unpaid accounts don't have the playback feature so I haven't really tested this script out very well. Sorry. Just let me know if something seems off and IF I have time I'll try to fix it.
2)Keep in mind that Pinescript limits the number of lines that can be shown at one time. This means that if your settings allow for a large number of divergence lines they will be removed from the leftward side of your chart but appear in the rightward side.
3) The time and the values for the price or oscillator are not the same things as each other nor are they physical things with physical space. This means that slopes of lines using the time as X and value as Y can not have definite angles. Consequently, under the setting "DIVERGENCES: SLOPE ANGLE EXCLUSION" YOU have to decide what slope equals what angle by using the setting called "Normalization Factor".
4) Remember that some individual settings apply to both the oscillator and price chart. This means that even if the setting's conditions are fulfilled in one they may not be fulfilled in the other.
5) Under the category "DIVERGENCES: INTERSECTION ALLOWANCE", if you set the "Measurement Type" to Relative Percentage then FYI any single given length will equate to an increasingly smaller percentage the further away from zero it is. Because of this, I think "Reletive Percentage" is probably only useful for price charts or oscillators with big values. Maybe >200 is OK ?
Errors:
1) If you get the error mentioning that the script must complete execution within X amount of time, this is because this is a big script and sometimes takes longer than your service plan's allotted time limit. You can just disable some of the settings to reduce the scripts amount of work and time. The biggest time savers will be to disable some lines and labels
2) If you get an error saying the script accessed a negative index(e.g. ) then try temporarily increasing the "Add More Array Elements" setting to 100-200. Sometimes it fixes the problem.
3) You may sometimes temporarily get an error that reads: "Pine cannot determine the referencing length of a series. Try using max_bars_back in the study or strategy function".
If this happens there are several things that you can do:
3A) Create a copy of my script. Then edit the section of code that looks like this ")//, max_bars_back = INSERT_YOUR_QUANTITY_HERE)" and transform it to look like this new code ", max_bars_back = INSERT_YOUR_QUANTITY_HERE)" then repeatedly try replacing "INSERT_YOUR_QUANTITY_HERE" with an increasingly larger number greater than 244 but less than 5000.
This method will increase your system resources and could cause other problems. Try changing the code back after a few hours and see if all is well again. It is a Pinescript limitation issue and happens when certain functions or variables don't get used at least once within the first 244 bars.
3B) Adjust your settings to hopefully find a divergence within the first 244 bars. If one is found then the problematic variables or functions should get used and the Pinescript 244 bar limitation should be temporarily resolved.
3C) Wait for X number of new bars to occur. If a divergence is eventually found within the first 244 bars that should solve the issue.
Tips:
1) If the amount that a setting changes value is undesirable for each time you click it then you can change that amount in the code. To do that, you'll need your own copy of my script. To make your own copy just click on "create a working copy" in the brown colored strip area above the code. Then within approximately the first 108 lines find the title of the setting you want to change. Then look to it's right to find the parameter called "step =". Change what the step equals to whatever you want. FYI, you can hover your mouse over the blue colored code and a popup will tell you what parameters(i.e. settings) that function(e.g. "input.int()") has available.
Delta Volume Channels [LucF]█ OVERVIEW
This indicator displays on-chart visuals aimed at making the most of delta volume information. It can color bars and display two channels: one for delta volume, another calculated from the price levels of bars where delta volume divergences occur. Markers and alerts can also be configured using key conditions, and filtered in many different ways. The indicator caters to traders who prefer chart visuals over raw values. It will work on historical bars and in real time, using intrabar analysis to calculate delta volume in both conditions.
█ CONCEPTS
Delta Volume
The volume delta concept divides a bar's volume in "up" and "down" volumes. The delta is calculated by subtracting down volume from up volume. Many calculation techniques exist to isolate up and down volume within a bar. The simplest techniques use the polarity of interbar price changes to assign their volume to up or down slots, e.g., On Balance Volume or the Klinger Oscillator . Others such as Chaikin Money Flow use assumptions based on a bar's OHLC values. The most precise calculation method uses tick data and assigns the volume of each tick to the up or down slot depending on whether the transaction occurs at the bid or ask price. While this technique is ideal, it requires huge amounts of data on historical bars, which usually limits the historical depth of charts and the number of symbols for which tick data is available.
This indicator uses intrabar analysis to achieve a compromise between the simplest and most precise methods of calculating volume delta. In the context where historical tick data is not yet available on TradingView, intrabar analysis is the most precise technique to calculate volume delta on historical bars on our charts. TradingView's Volume Profile built-in indicators use it, as do the CVD - Cumulative Volume Delta Candles and CVD - Cumulative Volume Delta (Chart) indicators published from the TradingView account . My Volume Delta Columns Pro indicator also uses intrabar analysis. Other volume delta indicators such as my Realtime 5D Profile use realtime chart updates to achieve more precise volume delta calculations. Indicators of that type cannot be used on historical bars however; they only work in real time.
This is the logic I use to assign intrabar volume to up or down slots:
• If the intrabar's open and close values are different, their relative position is used.
• If the intrabar's open and close values are the same, the difference between the intrabar's close and the previous intrabar's close is used.
• As a last resort, when there is no movement during an intrabar and it closes at the same price as the previous intrabar, the last known polarity is used.
Once all intrabars making up a chart bar have been analyzed and the up or down property of each intrabar's volume determined, the up volumes are added and the down volumes subtracted. The resulting value is volume delta for that chart bar, which can be used as an estimate of the buying/selling pressure on an instrument.
Delta Volume Percent (DV%)
This value is the proportion that delta volume represents of the total intrabar volume in the chart bar. Note that on some symbols/timeframes, the total intrabar volume may differ from the chart's volume for a bar, but that will not affect our calculations since we use the total intrabar volume.
Delta Volume Channel
The DV channel is the space between two moving averages: the reference line and a DV%-weighted version of that reference. The reference line is a moving average of a type, source and length which you select. The DV%-weighted line uses the same settings, but it averages the DV%-weighted price source.
The weight applied to the source of the reference line is calculated from two values, which are multiplied: DV% and the relative size of the bar's volume in relation to previous bars. The effect of this is that DV% values on bars with higher total volume will carry greater weight than those with lesser volume.
The DV channel can be in one of four states, each having its corresponding color:
• Bull (teal): The DV%-weighted line is above the reference line.
• Strong bull (lime): The bull condition is fulfilled and the bar's close is above the reference line and both the reference and the DV%-weighted lines are rising.
• Bear (maroon): The DV%-weighted line is below the reference line.
• Strong bear (pink): The bear condition is fulfilled and the bar's close is below the reference line and both the reference and the DV%-weighted lines are falling.
Divergences
In the context of this indicator, a divergence is any bar where the slope of the reference line does not match that of the DV%-weighted line. No directional bias is assigned to divergences when they occur.
Divergence Channel
The divergence channel is the space between two levels (by default, the bar's low and high ) saved when divergences occur. When price has breached a channel and a new divergence occurs, a new channel is created. Until that new channel is breached, bars where additional divergences occur will expand the channel's levels if the bar's price points are outside the channel.
Prices breaches of the divergence channel will change its state. Divergence channels can be in one of five different states:
• Bull (teal): Price has breached the channel to the upside.
• Strong bull (lime): The bull condition is fulfilled and the DV channel is in the strong bull state.
• Bear (maroon): Price has breached the channel to the downside.
• Strong bear (pink): The bear condition is fulfilled and the DV channel is in the strong bear state.
• Neutral (gray): The channel has not been breached.
█ HOW TO USE THE INDICATOR
Load the indicator on an active chart (see here if you don't know how).
The default configuration displays:
• The DV channel, without the reference or DV%-weighted lines.
• The Divergence channel, without its level lines.
• Bar colors using the state of the DV channel.
The default settings use an Arnaud-Legoux moving average on the close and a length of 20 bars. The DV%-weighted version of it uses a combination of DV% and relative volume to calculate the ultimate weight applied to the reference. The DV%-weighted line is capped to 5 standard deviations of the reference. The lower timeframe used to access intrabars automatically adjusts to the chart's timeframe and achieves optimal balance between the number of intrabars inspected in each chart bar, and the number of chart bars covered by the script's calculations.
The Divergence channel's levels are determined using the high and low of the bars where divergences occur. Breaches of the channel require a bar's low to move above the top of the channel, and the bar's high to move below the channel's bottom.
No markers appear on the chart; if you want to create alerts from this script, you will need first to define the conditions that will trigger the markers, then create the alert, which will trigger on those same conditions.
To learn more about how to use this indicator, you must understand the concepts it uses and the information it displays, which requires reading this description. There are no videos to explain it.
█ FEATURES
The script's inputs are divided in four sections: "DV channel", "Divergence channel", "Other Visuals" and "Marker/Alert Conditions". The first setting is the selection method used to determine the intrabar precision, i.e., how many lower timeframe bars (intrabars) are examined in each chart bar. The more intrabars you analyze, the more precise the calculation of DV% results will be, but the less chart coverage can be covered by the script's calculations.
DV Channel
Here, you control the visibility and colors of the reference line, its weighted version, and the DV channel between them.
You also specify what type of moving average you want to use as a reference line, its source and length. This acts as the DV channel's baseline. The DV%-weighted line is also a moving average of the same type and length as the reference line, except that it will be calculated from the DV%-weighted source used in the reference line. By default, the DV%-weighted line is capped to five standard deviations of the reference line. You can change that value here. This section is also where you can disable the relative volume component of the weight.
Divergence Channel
This is where you control the appearance of the divergence channel and the key price values used in determining the channel's levels and breaching conditions. These choices have an impact on the behavior of the channel. More generous level prices like the default low and high selection will produce more conservative channels, as will the default choice for breach prices.
In this section, you can also enable a mode where an attempt is made to estimate the channel's bias before price breaches the channel. When it is enabled, successive increases/decreases of the channel's top and bottom levels are counted as new divergences occur. When one count is greater than the other, a bull/bear bias is inferred from it.
Other Visuals
You specify here:
• The method used to color chart bars, if you choose to do so.
• The display of a mark appearing above or below bars when a divergence occurs.
• If you want raw values to appear in tooltips when you hover above chart bars. The default setting does not display them, which makes the script faster.
• If you want to display an information box which by default appears in the lower left of the chart.
It shows which lower timeframe is used for intrabars, and the average number of intrabars per chart bar.
Marker/Alert Conditions
Here, you specify the conditions that will trigger up or down markers. The trigger conditions can include a combination of state transitions of the DV and the divergence channels. The triggering conditions can be filtered using a variety of conditions.
Configuring the marker conditions is necessary before creating an alert from this script, as the alert will use the marker conditions to trigger.
Markers only appear on bar closes, so they will not repaint. Keep in mind, when looking at markers on historical bars, that they are positioned on the bar when it closes — NOT when it opens.
Raw values
The raw values calculated by this script can be inspected using a tooltip and the Data Window. The tooltip is visible when you hover over the top of chart bars. It will display on the last 500 bars of the chart, and shows the values of DV, DV%, the combined weight, and the intermediary values used to calculate them.
█ INTERPRETATION
The aim of the DV channel is to provide a visual representation of the buying/selling pressure calculated using delta volume. The simplest characteristic of the channel is its bull/bear state. One can then distinguish between its bull and strong bull states, as transitions from strong bull to bull states will generally happen when buyers are losing steam. While one should not infer a reversal from such transitions, they can be a good place to tighten stops. Only time will tell if a reversal will occur. One or more divergences will often occur before reversals.
The nature of the divergence channel's design makes it particularly adept at identifying consolidation areas if its settings are kept on the conservative side. A gray divergence channel should usually be considered a no-trade zone. More adventurous traders can use the DV channel to orient their trade entries if they accept the risk of trading in a neutral divergence channel, which by definition will not have been breached by price.
If your charts are already busy with other stuff you want to hold on to, you could consider using only the chart bar coloring component of this indicator:
At its simplest, one way to use this indicator would be to look for overlaps of the strong bull/bear colors in both the DV channel and a divergence channel, as these identify points where price is breaching the divergence channel when buy/sell pressure is consistent with the direction of the breach. I have highlighted all those points in the chart below. Not all of them would have produced profitable trades, but nothing is perfect in the markets. Also, keep in mind that the circles identify the visual you would be looking for — not the trade's entry level.
█ LIMITATIONS
• The script will not work on symbols where no volume is available. An error will appear when that is the case.
• Because a maximum of 100K intrabars can be analyzed by a script, a compromise is necessary between the number of intrabars analyzed per chart bar
and chart coverage. The more intrabars you analyze per chart bar, the less coverage you will obtain.
The setting of the "Intrabar precision" field in the "DV channel" section of the script's inputs
is where you control how the lower timeframe is calculated from the chart's timeframe.
█ NOTES
Volume Quality
If you use volume, it's important to understand its nature and quality, as it varies with sectors and instruments. My Volume X-ray indicator is one way you can appraise the quality of an instrument's intraday volume.
For Pine Script™ Coders
• This script uses the new overload of the fill() function which now makes it possible to do vertical gradients in Pine. I use it for both channels displayed by this script.
• I use the new arguments for plot() 's `display` parameter to control where the script plots some of its values,
namely those I only want to appear in the script's status line and in the Data Window.
• I wrote my script using the revised recommendations in the Style Guide from the Pine v5 User Manual.
█ THANKS
To PineCoders . I have used their lower_tf library in this script, to manage the calculation of the LTF and intrabar stats, and their Time library to convert a timeframe in seconds to a printable form for its display in the Information box.
To TradingView's Pine Script™ team. Their innovations and improvements, big and small, constantly expand the boundaries of the language. What this script does would not have been possible just a few months back.
And finally, thanks to all the users of my scripts who take the time to comment on my publications and suggest improvements. I do not reply to all but I do read your comments and do my best to implement your suggestions with the limited time that I have.

Template Trailing Strategy (Backtester)💭 Overview
+ Title: Template Trailing Strategy (Backtester)
+ Author: Iason Nikolas (jason5480)
+ License: CC BY-NC-SA 4.0
💢 What is the "Template Trailing Strategy (Backtester)" ❓
The "Template Trailing Strategy (Backtester)" (TTS) is a back-tester orchestration framework. It supercharges the implementation-test-evaluation lifecycle of new trading strategies, by making it possible to plug in your own trading idea.
While TTS offers a vast number of configuration settings, it primarily allows the trader to:
Test and evaluate your own trading logic that is described in terms of entry, exit, and cancellation conditions.
Define the entry and exit order types as well as their target prices when the limit, stop, or stop-limit order types are used.
Utilize a variety of options regarding the placement of the stop-loss and take-profit target(s) prices and support for well-known techniques like moving to breakeven and trailing.
Provide well-known quantity calculation methods to properly handle risk management and easily evaluate trading strategies and compare them.
Alert on each trading event or any related change through a robust and fully customizable messaging system.
All of the above makes TTS a practical toolkit: once you learn it, many repetitive tasks that strategy authors usually re-implement are eliminated. Using TradingView’s built-in backtesting engine makes testing and comparing ideas straightforward.
By utilizing the TTS one can easily swap "trading logic" by testing, evaluating, and comparing each trading idea and/or individual component of a strategy.
Finally, TTS, through its per-event alert management (and debugging) system, provides an automated solution that supports live trading with brokers via webhooks.
NOTE: The "Template Trailing Strategy (Backtester)" does not dictate how you can combine different indicator types. Thus, it should not be confused as a "Trading System", because it gives its user full flexibility on that end (for better or worse).
💢 What is a "Signal Indicator" ❓
"Signal Indicator" (SI) is an indicator that can output a "signal" that follows a specific convention so that the "Template Trailing Strategy (Backtester)" can "understand" and execute the orders accordingly. The SI realizes the core trading logic signaling to the TTS when to enter, exit, or cancel an order. A SI instructs the TTS "when" to enter or exit, and the TTS determines "how" to enter and exit the position once the Signal Indicator generates a signal.
A very simple example of a Signal Indicator might be a 200-day Simple Moving Average Signal. When the price of the security closes above the 200-day SMA, a SI would provide TTS with a "long entry signal". Once TTS receives the "long entry signal", the TTS will open a long position and send an alert or automated trade message via webhook to a broker, based on the Entry settings defined in TTS. If the TTS Entry settings specify a "Market" order type, then the open long position will be executed by TTS immediately. But if the TTS Entry settings specify a "Stop" order type with a 1% Stop Distance, then when the price of the security rises by 1% after the "long entry signal" occurs, the TTS will open a long position and the Long Entry alert or webhook to the broker will be sent.
🤔 How to Guide
💢 How to connect a "signal" from a "Signal Indicator" ❓
The "Template Trailing Strategy (Backtester)" was designed to receive external signals from a "Signal Indicator". In this way, a "new trading idea" can be developed, configured, and evaluated separately from the TTS. Similarly, the SI can be held constant, and the trading mechanics can change in the TTS settings and back-tested to answer questions such as, "Am I better with a different stop loss placement method, what if I used a limit order instead of a stop order to enter, what if I used 25% margin instead of trading spot market?"
To make that possible by connecting an external signal indicator to TTS, you should:
Add both your SI (e.g. "Two MA Signal Indicator" , "Click Signal Indicator" , "Signal Adapter" , "Signal Composer" ) and the TTS script to the same chart.
Open the script's Settings / Inputs dialog for the TTS.
In the 🛠️ STRATEGY group set 𝐃𝐞𝐚𝐥 𝐂𝐨𝐧𝐝𝐢𝐨𝐧𝐬 𝐌𝐨𝐝𝐞 to 🔨External (this makes TTS listen to an external signal source).
Still inside 🛠️ STRATEGY locate the 🔌𝐒𝐢𝐠𝐧𝐚𝐥 🛈 input and choose the plotted output of your SI. The option should look like: "<SI short title>:🔌Signal to TTS" .
Verbose troubleshooting & tips
If the SI does not appear in the 🔌Signal 🛈 selector, confirm both scripts are added to the same chart and the SI exposes a plotted series (title often "🔌Signal to TTS").
When using multiple SIs, pick the SI instance that actually outputs the "🔌Signal to TTS" plotted series.
Validate on the chart: when your SI changes state, the plotted "🔌Signal" series in the TTS (visible in the data window) should change accordingly.
The TTS accepts only signals that follow the tts_convention DealConditions structure. Do not attempt to feed arbitrary scalar series without using conv.getDealConditions / conv.DealConditions.
Make sure your SI composes a DealConditions value following the TTS convention (startLong, endLong, startShort, endShort — optional cancel fields). See the template below.
If the plot is present but TTS does not react, ensure the SI plot is non-repainting (or accept realtime/backtest limitations). Test on historical bars first.
Create alerts on the strategy (see the Alerts section). Use the {{strategy.order.alert_message}} placeholder in the Create Alert dialog to forward TTS messages.
💢 How to create a custom trading logic ❓
The "Template Trailing Strategy (Backtester)" provides two ways to plug in your custom trading logic. Both of them have their advantages and disadvantages.
✍️ Develop your own Customized "Signal Indicator" 💥
The first approach is meant to be used for relatively more complex trading logic. The advantages of this approach are the full control and customization you have over the trading logic and the relatively simple configuration setup by having two scripts only. The downsides are that you have to have some experience with pinescript or you are willing to learn and experiment. You should also know the exact formula for every indicator you will use since you have to write it by yourself. Copy-pasting from existing open-source indicators will get you started quite fast though.
The idea here is either to create a new indicator script from scratch or to copy an existing non-signal indicator and make it a "Signal Indicator". To create a new script, press the "Pine Editor" button below the chart to open the "Pine Editor" and then press the "Open" button to open the drop-down menu with the templates. Select the "New Indicator" option. Add it to your chart to copy an existing indicator and press the source code {} button. Its source code will be shown in the "Pine Editor" with a warning on top stating that this is a read-only script. Press the "create a working copy". Now you can give a descriptive title and a short title to your script, and you can work on (or copy-paste) the (other) indicators of your interest. Once you have the information needed to decide, define a DealConditions object and plot it like this:
import jason5480/tts_convention/ as conv
// Calculate the start, end, cancel start, cancel end conditions
dealConditions = conv.DealConditions.new(
startLongDeal = ,
startShortDeal = ,
endLongDeal = ,
endShortDeal = ,
cnlStartLongDeal = ,
cnlStartShortDeal = ,
cnlEndLongDeal = ,
cnlEndShortDeal = )
// Use this signal in scripts like "Template Trailing Strategy (Backtester)" and "Signal Composer" that can utilize its value
// Emit the current signal value according to the TTS framework convention
plot(series = conv.getSignal(dealConditions), title = '🔌Signal to TTS', color = #808000, editable = false, display = display.data_window + display.status_line, precision = 0)
You should import the latest version of the tts_convention library and write your deal conditions appropriately based on your trading logic and put them in the code section shown above by replacing the "…" part after "=". You can omit the conditions that are not relevant to your logic. For example, if you use only market orders for entering and exiting your positions the cnlStartLongDeal, cnlStartShortDeal, cnlEndLongDeal, and cnlEndShortDeal are irrelevant to your case and can be safely omitted from the DealConditions object. After successfully compiling your new custom SI script add it to the same chart with the TTS by pressing the "Add to chart" button. If all goes well, you will be able to connect your "signal" to the TTS as described in the "How to connect a "signal" from a "Signal Indicator"?" guide.
🧩 Adapt and Combine existing non-signal indicators 💥
The second approach is meant to be used for relatively simple trading logic. The advantages of this approach are the lack of pine script and coding experience needed and the fact that it can be used with closed-source indicators as long as the decision-making part is displayed as a line in the chart. The drawback is that you have to have a subscription that supports the "indicator on indicator" feature so you can connect the output of one indicator as an input to another indicator. Please check if your plan supports that feature here
To plug in your own logic that way you have to add your indicator(s) of preference in the chart and then add the "Signal Adapter" script in the same chart as well. This script is a "Signal Indicator" that can be used as a proxy to define your custom logic in the CONDITIONS group of the "Settings/Inputs" tab after defining your inputs from your preferred indicators in the VARIABLES group. Then a "signal" will be produced, if your logic is simple enough it can be directly connected to the TTS that is also added to the same chart for execution. Check the "How to connect a "signal" from a "Signal Indicator"?" in the "🤔 How to Guide" for more information.
If your logic is slightly more complicated, you can add a second "Signal Adapter" in your chart. Then you should add the "Signal Composer" in the same chart, go to the SIGNALS group of the "Settings/Inputs" tab, and connect the "signals" from the "Signal Adapters". "Signal Composer" is also a SI so its composed "signal" can be connected to the TTS the same way it is described in the "How to connect a "signal" from a "Signal Indicator"?" guide.
At this point, due to the composability of the framework, you can add an arbitrary number (bounded by your subscription of course) of "Signal Adapters" and "Signal Composers" before connecting the final "signal" to the TTS.
💢 How to set up ⏰Alerts ❓
The "Template Trailing Strategy (Backtester)" provides a fully customizable per-event alert mechanism. This means that you may have an entirely different message for entering and exiting into a position, hitting a stop-loss or a take-profit target, changing trailing targets, etc. There are no restrictions, and this gives you great flexibility.
First enable the events you want under the "🔔 ALERT MESSAGES" module. Each enabled event exposes a text area where you can craft the message using placeholders that TTS replaces with actual values when the event occurs.
The placeholder categories (exact names used by the script) are:
Chart & instrument:
{{ticker}}
{{base_currency}}
{{quote_currency}}
Entry / exit / stop / TP prices & offsets:
{{entry_price}}
{{exit_price}}
{{stop_loss_price}}
{{take_profit_price_1}} ... {{take_profit_price_5}}
{{entry+_price}}, {{entry-_price}}, {{exit+_price}}, {{exit-_price}} — Optional offset helpers (computed using "Offset Ticks")
Quantities, percents & derived quantities:
{{entry_base_quantity}} — base units at entry (e.g. BTC)
{{entry_quote_quantity}} — quote amount at entry (e.g. USD)
{{risk_perc}} — % of capital risked for that entry (multiplied by 100 when "Percentage Range " is enabled)
{{remaining_quantity_perc}} — % of the initial position remaining at close/SL
{{remaining_base_quantity}} — remaining base units at close/SL
{{take_profit_quantity_perc_1}} ... {{take_profit_quantity_perc_5}} — % sold/bought at each TP
{{take_profit_base_quantity_1}} ... {{take_profit_base_quantity_5}} — base units closed at each TP
❗ Important: the per-event alert text is injected into the Create Alert dialog using TradingView's strategy placeholder:
{{strategy.order.alert_message}}
During the creation of a strategy alert, make sure the placeholder {{strategy.order.alert_message}} exists in the "Message" box. TradingView will substitute the per-event text you configured and enabled in TTS Settings/Inputs before sending it via webhook/notification.
Tip: For webhook/broker execution, set the proper "Condition" in the Create Alert dialog (for changing-entry/exit/SL notifications use "Order fills and alert() function calls" or "alert() function calls only" as appropriate).
💢 How to execute my orders in a broker ❓
To execute your orders in a broker that supports webhook integration, you should enable the appropriate alerts in the "Template Trailing Strategy (Backtester)" first (see the "How to set up Alerts?" guide above). Then you should go to the "Create Alert/Notifications" tab check the "Webhook URL" and paste the URL provided by your broker. You have to read the documentation of your broker for more information on what messages are expected.
Keep in mind that some brokers have deep integration with TradingView so a per-event alert approach might be overkill.
📑 Definitions
This section tries to give some definitions in terms that appear in the "Settings/Inputs" tab of the "Template Trailing Strategy (Backtester)"
💢 What is Trailing ❓
Trailing is a technique where a price target follows another "barrier" price (usually high or low) by trying to keep a maximum distance from the "barrier" when it moves in only one direction (up or down). When the "barrier" moves in the other direction the price target will not change. There are as many types of trailing as price targets, which means that there are entry trailing, exit trailing, stop-loss trailing, and take-profit trailing techniques.
💢 What is a Moonbag ❓
A Moonbag in a trade is the quantity of the position that is reserved and will not be exited even if all take-profit targets defined in the strategy are hit, the quantity will be exited only if the stop-loss is hit or a close signal is received. This makes the stop-loss trailing technique in a trend-following strategy a good candidate to take advantage of a Moonbag.
💢 What is Distance ❓
Distance is the difference between two prices.
💢 What is Bias ❓
Bias is a psychological phenomenon where you make decisions based on market sentiment. For example, when you want to enter a long position you have a long bias, and when you want to exit from the long position you have a short bias. It is the other way around for the short position.
💢 What is the Bias Distance of a price target ❓
The Bias Distance of a price target is the distance that the target will deviate from its initial price. The direction of this deviation depends on the bias of the market. For example, suppose you are in a long position, and you set a take-profit target to the local highest high. In that case, adding a bias distance of five ticks will place your take-profit target 5 ticks below this local highest high because you have a short bias when exiting a long position. When the bias is long the bias distance will be added resulting in a higher target price and when you have a short bias the bias distance will be subtracted.
⚙️ Settings
In the "Settings/Inputs" tab of the "Template Trailing Strategy (Backtester)", you can find all the customizable settings that are provided by the framework. The variety of those settings is vast; hence we will only scratch the surface here. However, for every setting, there is an information icon 🛈 where you can learn more if you mouse over it. The "Settings/Inputs" tab is divided into ten main groups. Each one of them is responsible for one module of the framework. Every setting is part of a group that is named after the module it represents. So, to spot the module of a setting find the title that appears above it comes with an emoji and uppercase letters. Some settings might have the same name but belong to different modules e.g. "Tgt Dist Mtd" (Target Distance Method). Some settings are indented, which means that they are closely related to the non-indented setting above. Usually, indented settings provide further configuration for one or more options of the non-indented setting above. The groups that correspond to each module of the framework are the following:
🗺️ Quick Module Cross-Reference (use emojis to jump to setting groups)
📆 FILTERS — session, date & weekday filters
🛠️ STRATEGY — internal vs external deal-conditions; pick the signal source
🔧 STRATEGY – INTERNAL — built-in Two MA logic for demonstration purposes
🎢 VOLATILITY — ATR / StDev update modes
🔷 ENTRY — entry order types & trailing
🎯 TAKE PROFIT — multi-step TP and trailing rules
🛑 STOP LOSS — stop placement, move-to-breakeven, trailing
🟪 EXIT — exit order types & cancel logic
💰 QUANTITY/RISK MANAGEMENT — position sizing, moonbag, limits
📊 ANALYTICS — stats, streaks, seasonal tables
🔔 ALERT MESSAGES — per-event alert templates & placeholders
😲 Caveats
💢 Does "Template Trailing Strategy (Backtester)" have repainting behavior? ❓
The answer is that the "Template Trailing Strategy (Backtester)" does not repaint as long as the "Signal Indicator" that is connected also does not repaint. If you developed your own SI make sure that you understand and know how to prevent this behavior. The publication by @PineCoders here will give you a good idea on how to avoid most of the repainting cases.
⚠️ There is an exception though, when the "Enable Trail⚠️💹" checkbox is checked, the Take Profit trailing feature is enabled, and a tick-based approach is used, meaning that after a while, when the TradingView discards all the real-time data, assumptions will be made by the backtesting engine that will cause a form of repainting. To avoid making false assumptions please disable this feature in the early stages and evaluate its usefulness in your strategy later on, after first confirming the success of the logic without this feature. In this case, consider turning on the bar magnifier feature. This way you will get more accurate backtest results when the Take Profit trailing feature is enabled.
💢 Can "Template Trailing Strategy (Backtester)" satisfy all my trading strategies ❓
While this framework can satisfy quite a large number of trading strategies there are cases where it cannot do so. For example, if you have a custom logic for your stop-loss or take-profit placement, or if you want to dollar cost average, then it might be better to start a new strategy script from scratch.
⚠️ It is not recommended to copy the official TTS code and start developing unless you are a Pine wizard! Even in that case, there is a stiff learning curve that might not be worth your time. Last, you must consider that I do not offer support for customized versions of the TTS script and if something goes wrong in the process you are all alone.
💝 Support & Feedback
For feedback, bug reports, or feature requests, contact me via TradingView PM or use the script comments.
Note: The author's personal links and contact are available on the TradingView profile.
🤗 Thanks
Special thanks to the welcoming community members, who regularly gave feedback all those years and helped me to shape the framework as it is today! Thanks everyone who contributed by either filing a "defect report" or asking questions that helped me to understand what improvements were necessary to help traders.
Enjoy!
Jason
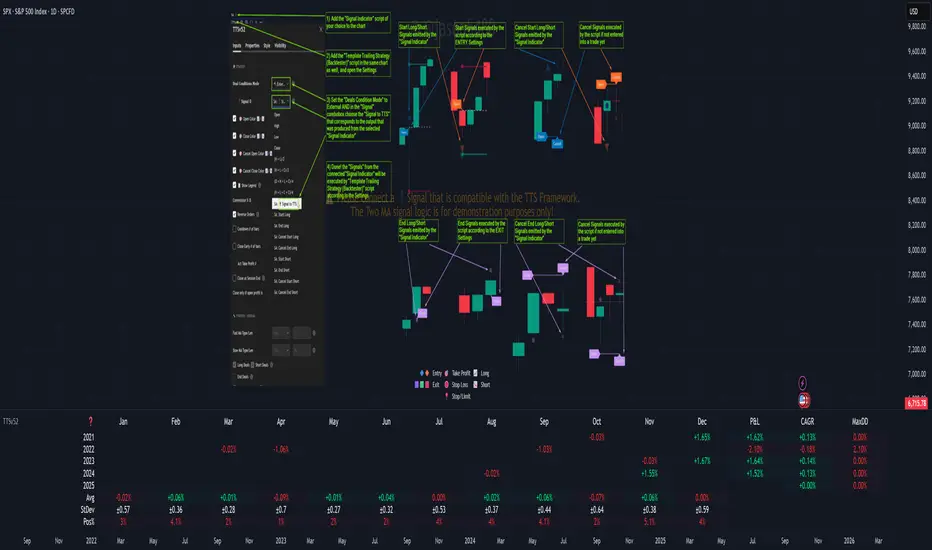
Scanner/Screener of Over 40 Coins Per Script I am very scatter-brained by nature and sporadic in my thought processes but if these benefit the community and ya'll ask for more perhaps I will get better and even out a tad....probably not....but you never know. Firstly, allow me to apologize to all the vet/more sophisticated coders out there whose eyes and brains might just be overly taxed due to my poor coding structure. Im just getting started for the first time in ANY sort of coding...so cut me a little slack. Also, if anyone sees any mistakes or the functionality is not as I proclaimed, PLEASE do let me know. In these past 12mo of me learning my 1st coding language (Pinescript) I would say that I have been intently focused on creating all types/sorts of scanners/screeners. Ive always hoped to be a benefit to the community as I was always SO grateful to those who have come before me that have led me to the little bit of progress I have made with Pinescript. This script is not necessarily something that should be traded with as it is just a thrown together example showing a scanner/screener whose results produce plot outputs (ie, Rate of Change / oscillators as well / etc) and how they can be used in the alert system so that only 1 alert has to be set per iteration of the script but more importantly how to use/scan/screen with over 40 coins per script. My intent is not to trick anyone here. So to be PERFECTLY CLEAR, more than 40 coins CAN in fact be screened/scanned from one script (here I am doing all of KUCOIN's Margin Coins...72 total I look at)...BUT...(heres the catch) it must be added to the chart however many times EQUAL to the amount of "sets" you have in your script. (Heres the limitation by TV) There cannot be more than 40 coins in each "set". The less coins you have per set, the quicker the script will startup and run, thus, the quicker alerts will be received if automating the process. Though, if you only have the free plan and can only have MAX 3 indicators per chart then the MAX you can screen at a time is 120 coins if you use 40 coins per set. So, this is the first one I would like to introduce. For this one your screener/scanner must be using some sort of plots as output that is being screened for. (original inspiration of ALL my variations mainly come from @QuantNomad, @daveatt, and @LonesomeTheBlue (and a few others I may be forgetting at the moment). Thanks for the inspiration through countless publications that ya'll have created for us in the community.
Some of my variations are more complex/elegant than others but there are MANY very different ones that I would like to share with the community. If you leave a comment and wonder why I have not responded but did so to every comment around yours...see if you are one of the individuals in this next few sentences...and if you are then perhaps someone else would like to waste their time responding to your comment...but basically, if you don't want to spend the time helping yourself by reading the title, description section, AND the comments section (at least scanning them) then I am MOST DEFINITELY not going to help you down your path of destruction that is most likely soon to be your blown-up trading account. I was called a "masochist" after asking for guidance on if its worth the headache to publish anything on TV bc there will NO DOUBT be comments that'll make me wish I didn't (ie. someone CLEARLY not reading the description (or seemingly even the title sometimes) bc they make a comment that has been explicitly addressed, or someone asking to rebuild the code compatible for another charting software or whatnot, or how about those asking if it repaints (this one is almost always addressed in the comments section but I can understand this question more than others as Im only 1 yr into learning any sort of coding for the first time in the beginning I saw people ask on EVERY script about if it repainted and it was worrisome at the lest (esp bc I didn't even understand what it was not so long ago, or my favorite...what TF it works best on...these people CLEARLY need not be trading yet if your still asking questions as such...Ill end it there). Point being, Ive got some truly VERY useful scripts that I want to share and as long as these people don't make me regret doing so in the beginning, then whats mine...will soon be yours. Though, I will take a little time between the releases.
YOU GUYS (TV and its community) ARE AWESOME (most of you anyways ;)
MUCH LOVE,
ChasinAlts
(1) INPUTS
Here is where the "sets" come in. I am looking at all of KUCOIN's Margin Coins (72 of them at least) so am splitting them up into 3 sets/iterations and a copy of the script must be added equal to amount of "sets" you have here. This is the ONLY workaround I have found to be able to scan/screen with more than 40 coins per script (due to TV's limitation of 40 Security Calls per script) ***So for everyone saying it's impossible scan more than 40 Coins per scipt...it' MOST DEFINITELY possible....BUT ONLY by adding this script multiple times on the chart and selecting 1 of each of the "sets" in the script settings via the chart window. To save the much needed room you must push each iteration of the script into 1 window and merging the scales of each into 1 scale(ie. "Scale A") within the settings of the script name on the chart(3 horizontal dots)
(2) FUNCTION
(2.1) COLORIDs
This is just to set up all my Colors of plots which are being matched with their respective labels. I have a diff color for each of the 72 coins Im plotting so Im telling the function, "depending on which set of coins I select...give me this color out of the colors I input later into the function"
(2.2) TICKERID CONSTRUCTION
I construct the tickerID this way so that the labels on my plots have only the Coin's name vs the label having the (Exchange Name):(Coin Name)(Base Pair Name). If you are using more than 1 Base pair (ie. XRP/BTC and XRP/USDT and XRP/ETH) OR more than 1 Exchange OR want your plots to show MORE THAN just the Trading Coin's name, then the tickerID MUST BE constructed differently
(2.3) SECURITY CALL & PLOT OUTPUT VARIABLES
If using a Higher Time Frame in Security Call then it MUST BE adjusted to permit or dissallow repainting if you so wish (BEYOND THE SCOPE OF THIS PUBLICATION so Do Your Own Researh). If your MAIN LOGIC is more complex than simply using a TV built-in function), THEN it MUST BE built into its own function outside of this function and called on within the "expression" slot of this Security Call OR can also be built into this function and called on in the "expression" slot of this Security call (BEYOND THE SCOPE OF THIS PUB SO DYOR). FURTHERMORE...when you are using a series(ie high/low/close/open/hl2/etc) / bar_index / time / etc that will be specific to the Coin/tickerID, then they MUST BE explicitly used within the "expression" slot of the Security Function when calling on your Main Logic or else it will pull the series/time/bar_index/etc from the Coin that the Chart is presently on (BEYOND THE SCOPE OF THIS PUB SO DYOR)
(2.4) PLOT LABEL
This is the Plot's Label that will be next to the end of the plot on the LAST bar_index. ***Notice in the "text" slot of the label I have "_coin" (without the quotes obviously)...this is where have JUST the Coin's name comes into effect on the label vs the (Exchange Name):(Coin Name)(Base Pair Name) which looks MUCH cleaner
(2.5) ALERT LOGIC / ALERT LABEL
Your alert logic need not be as complex as this... I just wanted to create a decent enough timing for this system and wanted to simply print the labels displaying which coin produced the alert at the same time the alerts would go off. Alert is set up to Trigger Bullish when the ROC is below the Threshold and _chg > _chg X=length of bars inputted in "Rising/Falling Length" setting and vise versa for Bearish Alerts. If _chg plot only goes past threshold for a VERY few amount of bars NOT providing enough time for initial Alert to trigger, then alert/label triggers on crossing of threshold back towards 0(zero). ONLY 1 alert needs to be set per script to be able to scan ALL 72 of the coins as I have them in this script. Timing of Alert is inline with the name label printed past the thresholds.
(3) VARIABLES FROM MAIN FUNCTION
This is the tuple of the Main Function that outputs the variables from 3 lines up to be able to plot the lines and color them according to the colors on the labels. *** As of now, we CANNOT plot from within the function so MUST BE done this way to produce the variables and colors needed. The plots are the ONLY thing in this script that cannot be executed from within the function
(4) LINE PLOTS
ALL output variables from our Main Function are used here for the line plots
Webhook Starter Kit [HullBuster]
Introduction
This is an open source strategy which provides a framework for webhook enabled projects. It is designed to work out-of-the-box on any instrument triggering on an intraday bar interval. This is a full featured script with an emphasis on actual trading at a brokerage through the TradingView alert mechanism and without requiring browser plugins.
The source code is written in a self documenting style with clearly defined sections. The sections “communicate” with each other through state variables making it easy for the strategy to evolve and improve. This is an excellent place for Pine Language beginners to start their strategy building journey. The script exhibits many Pine Language features which will certainly ad power to your script building abilities.
This script employs a basic trend follow strategy utilizing a forward pyramiding technique. Trend detection is implemented through the use of two higher time frame series. The market entry setup is a Simple Moving Average crossover. Positions exit by passing through conditional take profit logic. The script creates ten indicators including a Zscore oscillator to measure support and resistance levels. The indicator parameters are exposed through 47 strategy inputs segregated into seven sections. All of the inputs are equipped with detailed tool tips to help you get started.
To improve the transition from simulation to execution, strategy.entry and strategy.exit calls show enhanced message text with embedded keywords that are combined with the TradingView placeholders at alert time. Thereby, enabling a single JSON message to generate multiple execution events. This is genius stuff from the Pine Language development team. Really excellent work!
This document provides a sample alert message that can be applied to this script with relatively little modification. Without altering the code, the strategy inputs can alter the behavior to generate thousands of orders or simply a few dozen. It can be applied to crypto, stocks or forex instruments. A good way to look at this script is as a webhook lab that can aid in the development of your own endpoint processor, impress your co-workers and have hours of fun.
By no means is a webhook required or even necessary to benefit from this script. The setups, exits, trend detection, pyramids and DCA algorithms can be easily replaced with more sophisticated versions. The modular design of the script logic allows you to incrementally learn and advance this script into a functional trading system that you can be proud of.
Design
This is a trend following strategy that enters long above the trend line and short below. There are five trend lines that are visible by default but can be turned off in Section 7. Identified, in frequency order, as follows:
1. - EMA in the chart time frame. Intended to track price pressure. Configured in Section 3.
2. - ALMA in the higher time frame specified in Section 2 Signal Line Period.
3. - Linear Regression in the higher time frame specified in Section 2 Signal Line Period.
4. - Linear Regression in the higher time frame specified in Section 2 Signal Line Period.
5. - DEMA in the higher time frame specified in Section 2 Trend Line Period.
The Blue, Green and Orange lines are signal lines are on the same time frame. The time frame selected should be at least five times greater than the chart time frame. The Purple line represents the trend line for which prices above the line suggest a rising market and prices below a falling market. The time frame selected for the trend should be at least five times greater than the signal lines.
Three oscillators are created as follows:
1. Stochastic - In the chart time frame. Used to enter forward pyramids.
2. Stochastic - In the Trend period. Used to detect exit conditions.
3. Zscore - In the Signal period. Used to detect exit conditions.
The Stochastics are configured identically other than the time frame. The period is set in Section 2.
Two Simple Moving Averages provide the trade entry conditions in the form of a crossover. Crossing up is a long entry and down is a short. This is in fact the same setup you get when you select a basic strategy from the Pine editor. The crossovers are configured in Section 3. You can see where the crosses are occurring by enabling Show Entry Regions in Section 7.
The script has the capacity for pyramids and DCA. Forward pyramids are enabled by setting the Pyramid properties tab with a non zero value. In this case add on trades will enter the market on dips above the position open price. This process will continue until the trade exits. Downward pyramids are available in Crypto and Range mode only. In this case add on trades are placed below the entry price in the drawdown space until the stop is hit. To enable downward pyramids set the Pyramid Minimum Span In Section 1 to a non zero value.
This implementation of Dollar Cost Averaging (DCA) triggers off consecutive losses. Each loss in a run increments a sequence number. The position size is increased as a multiple of this sequence. When the position eventually closes at a profit the sequence is reset. DCA is enabled by setting the Maximum DCA Increments In Section 1 to a non zero value.
It should be noted that the pyramid and DCA features are implemented using a rudimentary design and as such do not perform with the precision of my invite only scripts. They are intended as a feature to stress test your webhook endpoint. As is, you will need to buttress the logic for it to be part of an automated trading system. It is for this reason that I did not apply a Martingale algorithm to this pyramid implementation. But, hey, it’s an open source script so there is plenty of room for learning and your own experimentation.
How does it work
The overall behavior of the script is governed by the Trading Mode selection in Section 1. It is the very first input so you should think about what behavior you intend for this strategy at the onset of the configuration. As previously discussed, this script is designed to be a trend follower. The trend being defined as where the purple line is predominately heading. In BiDir mode, SMA crossovers above the purple line will open long positions and crosses below the line will open short. If pyramiding is enabled add on trades will accumulate on dips above the entry price. The value applied to the Minimum Profit input in Section 1 establishes the threshold for a profitable exit. This is not a hard number exit. The conditional exit logic must be satisfied in order to permit the trade to close. This is where the effort put into the indicator calibration is realized. There are four ways the trade can exit at a profit:
1. Natural exit. When the blue line crosses the green line the trade will close. For a long position the blue line must cross under the green line (downward). For a short the blue must cross over the green (upward).
2. Alma / Linear Regression event. The distance the blue line is from the green and the relative speed the cross is experiencing determines this event. The activation thresholds are set in Section 6 and relies on the period and length set in Section 2. A long position will exit on an upward thrust which exceeds the activation threshold. A short will exit on a downward thrust.
3. Exponential event. The distance the yellow line is from the blue and the relative speed the cross is experiencing determines this event. The activation thresholds are set in Section 3 and relies on the period and length set in the same section.
4. Stochastic event. The purple line stochastic is used to measure overbought and over sold levels with regard to position exits. Signal line positions combined with a reading over 80 signals a long profit exit. Similarly, readings below 20 signal a short profit exit.
Another, optional, way to exit a position is by Bale Out. You can enable this feature in Section 1. This is a handy way to reduce the risk when carrying a large pyramid stack. Instead of waiting for the entire position to recover we exit early (bale out) as soon as the profit value has doubled.
There are lots of ways to implement a bale out but the method I used here provides a succinct example. Feel free to improve on it if you like. To see where the Bale Outs occur, enable Show Bale Outs in Section 7. Red labels are rendered below each exit point on the chart.
There are seven selectable Trading Modes available from the drop down in Section 1:
1. Long - Uses the strategy.risk.allow_entry_in to execute long only trades. You will still see shorts on the chart.
2. Short - Uses the strategy.risk.allow_entry_in to execute short only trades. You will still see long trades on the chart.
3. BiDir - This mode is for margin trading with a stop. If a long position was initiated above the trend line and the price has now fallen below the trend, the position will be reversed after the stop is hit. Forward pyramiding is available in this mode if you set the Pyramiding value in the Properties tab. DCA can also be activated.
4. Flip Flop - This is a bidirectional trading mode that automatically reverses on a trend line crossover. This is distinctively different from BiDir since you will get a reversal even without a stop which is advantageous in non-margin trading.
5. Crypto - This mode is for crypto trading where you are buying the coins outright. In this case you likely want to accumulate coins on a crash. Especially, when all the news outlets are talking about the end of Bitcoin and you see nice deep valleys on the chart. Certainly, under these conditions, the market will be well below the purple line. No margin so you can’t go short. Downward pyramids are enabled for Crypto mode when two conditions are met. First the Pyramiding value in the Properties tab must be non zero. Second the Pyramid Minimum Span in Section 1 must be non zero.
6. Range - This is a counter trend trading mode. Longs are entered below the purple trend line and shorts above. Useful when you want to test your webhook in a market where the trend line is bisecting the signal line series. Remember that this strategy is a trend follower. It’s going to get chopped out in a range bound market. By turning on the Range mode you will at least see profitable trades while stuck in the range. However, when the market eventually picks a direction, this mode will sustain losses. This range trading mode is a rudimentary implementation that will need a lot of improvement if you want to create a reliable switch hitter (trend/range combo).
7. No Trade. Useful when setting up the trend lines and the entry and exit is not important.
Once in the trade, long or short, the script tests the exit condition on every bar. If not a profitable exit then it checks if a pyramid is required. As mentioned earlier, the entry setups are quite primitive. Although they can easily be replaced by more sophisticated algorithms, what I really wanted to show is the diminished role of the position entry in the overall life of the trade. Professional traders spend much more time on the management of the trade beyond the market entry. While your trade entry is important, you can get in almost anywhere and still land a profitable exit.
If DCA is enabled, the size of the position will increase in response to consecutive losses. The number of times the position can increase is limited by the number set in Maximum DCA Increments of Section 1. Once the position breaks the losing streak the trade size will return the default quantity set in the Properties tab. It should be noted that the Initial Capital amount set in the Properties tab does not affect the simulation in the same way as a real account. In reality, running out of money will certainly halt trading. In fact, your account would be frozen long before the last penny was committed to a trade. On the other hand, TradingView will keep running the simulation until the current bar even if your funds have been technically depleted.
Entry and exit use the strategy.entry and strategy.exit calls respectfully. The alert_message parameter has special keywords that the endpoint expects to properly calculate position size and message sequence. The alert message will embed these keywords in the JSON object through the {{strategy.order.alert_message}} placeholder. You should use whatever keywords are expected from the endpoint you intend to webhook in to.
Webhook Integration
The TradingView alerts dialog provides a way to connect your script to an external system which could actually execute your trade. This is a fantastic feature that enables you to separate the data feed and technical analysis from the execution and reporting systems. Using this feature it is possible to create a fully automated trading system entirely on the cloud. Of course, there is some work to get it all going in a reliable fashion. Being a strategy type script place holders such as {{strategy.position_size}} can be embedded in the alert message text. There are more than 10 variables which can write internal script values into the message for delivery to the specified endpoint.
Entry and exit use the strategy.entry and strategy.exit calls respectfully. The alert_message parameter has special keywords that my endpoint expects to properly calculate position size and message sequence. The alert message will embed these keywords in the JSON object through the {{strategy.order.alert_message}} placeholder. You should use whatever keywords are expected from the endpoint you intend to webhook in to.
Here is an excerpt of the fields I use in my webhook signal:
"broker_id": "kraken",
"account_id": "XXX XXXX XXXX XXXX",
"symbol_id": "XMRUSD",
"action": "{{strategy.order.action}}",
"strategy": "{{strategy.order.id}}",
"lots": "{{strategy.order.contracts}}",
"price": "{{strategy.order.price}}",
"comment": "{{strategy.order.alert_message}}",
"timestamp": "{{time}}"
Though TradingView does a great job in dispatching your alert this feature does come with a few idiosyncrasies. Namely, a single transaction call in your script may cause multiple transmissions to the endpoint. If you are using placeholders each message describes part of the transaction sequence. A good example is closing a pyramid stack. Although the script makes a single strategy.close() call, the endpoint actually receives a close message for each pyramid trade. The broker, on the other hand, only requires a single close. The incongruity of this situation is exacerbated by the possibility of messages being received out of sequence. Depending on the type of order designated in the message, a close or a reversal. This could have a disastrous effect on your live account. This broker simulator has no idea what is actually going on at your real account. Its just doing the job of running the simulation and sending out the computed results. If your TradingView simulation falls out of alignment with the actual trading account lots of really bad things could happen. Like your script thinks your are currently long but the account is actually short. Reversals from this point forward will always be wrong with no one the wiser. Human intervention will be required to restore congruence. But how does anyone find out this is occurring? In closed systems engineering this is known as entropy. In practice your webhook logic should be robust enough to detect these conditions. Be generous with the placeholder usage and give the webhook code plenty of information to compare states. Both issuer and receiver. Don’t blindly commit incoming signals without verifying system integrity.
Setup
The following steps provide a very brief set of instructions that will get you started on your first configuration. After you’ve gone through the process a couple of times, you won’t need these anymore. It’s really a simple script after all. I have several example configurations that I used to create the performance charts shown. I can share them with you if you like. Of course, if you’ve modified the code then these steps are probably obsolete.
There are 47 inputs divided into seven sections. For the most part, the configuration process is designed to flow from top to bottom. Handy, tool tips are available on every field to help get you through the initial setup.
Step 1. Input the Base Currency and Order Size in the Properties tab. Set the Pyramiding value to zero.
Step 2. Select the Trading Mode you intend to test with from the drop down in Section 1. I usually select No Trade until I’ve setup all of the trend lines, profit and stop levels.
Step 3. Put in your Minimum Profit and Stop Loss in the first section. This is in pips or currency basis points (chart right side scale). Remember that the profit is taken as a conditional exit not a fixed limit. The actual profit taken will almost always be greater than the amount specified. The stop loss, on the other hand, is indeed a hard number which is executed by the TradingView broker simulator when the threshold is breached.
Step 4. Apply the appropriate value to the Tick Scalar field in Section 1. This value is used to remove the pipette from the price. You can enable the Summary Report in Section 7 to see the TradingView minimum tick size of the current chart.
Step 5. Apply the appropriate Price Normalizer value in Section 1. This value is used to normalize the instrument price for differential calculations. Basically, we want to increase the magnitude to significant digits to make the numbers more meaningful in comparisons. Though I have used many normalization techniques, I have always found this method to provide a simple and lightweight solution for less demanding applications. Most of the time the default value will be sufficient. The Tick Scalar and Price Normalizer value work together within a single calculation so changing either will affect all delta result values.
Step 6. Turn on the trend line plots in Section 7. Then configure Section 2. Try to get the plots to show you what’s really happening not what you want to happen. The most important is the purple trend line. Select an interval and length that seem to identify where prices tend to go during non-consolidation periods. Remember that a natural exit is when the blue crosses the green line.
Step 7. Enable Show Event Regions in Section 7. Then adjust Section 6. Blue background fills are spikes and red fills are plunging prices. These measurements should be hard to come by so you should see relatively few fills on the chart if you’ve set this up as intended. Section 6 includes the Zscore oscillator the state of which combines with the signal lines to detect statistically significant price movement. The Zscore is a zero based calculation with positive and negative magnitude readings. You want to input a reasonably large number slightly below the maximum amplitude seen on the chart. Both rise and fall inputs are entered as a positive real number. You can easily use my code to create a separate indicator if you want to see it in action. The default value is sufficient for most configurations.
Step 8. Turn off Show Event Regions and enable Show Entry Regions in Section 7. Then adjust Section 3. This section contains two parts. The entry setup crossovers and EMA events. Adjust the crossovers first. That is the Fast Cross Length and Slow Cross Length. The frequency of your trades will be shown as blue and red fills. There should be a lot. Then turn off Show Event Regions and enable Display EMA Peaks. Adjust all the fields that have the word EMA. This is actually the yellow line on the chart. The blue and red fills should show much less than the crossovers but more than event fills shown in Step 7.
Step 9. Change the Trading Mode to BiDir if you selected No Trades previously. Look on the chart and see where the trades are occurring. Make adjustments to the Minimum Profit and Stop Offset in Section 1 if necessary. Wider profits and stops reduce the trade frequency.
Step 10. Go to Section 4 and 5 and make fine tuning adjustments to the long and short side.
Example Settings
To reproduce the performance shown on the chart please use the following configuration: (Bitcoin on the Kraken exchange)
1. Select XBTUSD Kraken as the chart symbol.
2. On the properties tab set the Order Size to: 0.01 Bitcoin
3. On the properties tab set the Pyramiding to: 12
4. In Section 1: Select “Crypto” for the Trading Model
5. In Section 1: Input 2000 for the Minimum Profit
6. In Section 1: Input 0 for the Stop Offset (No Stop)
7. In Section 1: Input 10 for the Tick Scalar
8. In Section 1: Input 1000 for the Price Normalizer
9. In Section 1: Input 2000 for the Pyramid Minimum Span
10. In Section 1: Check mark the Position Bale Out
11. In Section 2: Input 60 for the Signal Line Period
12. In Section 2: Input 1440 for the Trend Line Period
13. In Section 2: Input 5 for the Fast Alma Length
14. In Section 2: Input 22 for the Fast LinReg Length
15. In Section 2: Input 100 for the Slow LinReg Length
16. In Section 2: Input 90 for the Trend Line Length
17. In Section 2: Input 14 Stochastic Length
18. In Section 3: Input 9 Fast Cross Length
19. In Section 3: Input 24 Slow Cross Length
20. In Section 3: Input 8 Fast EMA Length
21. In Section 3: Input 10 Fast EMA Rise NetChg
22. In Section 3: Input 1 Fast EMA Rise ROC
23. In Section 3: Input 10 Fast EMA Fall NetChg
24. In Section 3: Input 1 Fast EMA Fall ROC
25. In Section 4: Check mark the Long Natural Exit
26. In Section 4: Check mark the Long Signal Exit
27. In Section 4: Check mark the Long Price Event Exit
28. In Section 4: Check mark the Long Stochastic Exit
29. In Section 5: Check mark the Short Natural Exit
30. In Section 5: Check mark the Short Signal Exit
31. In Section 5: Check mark the Short Price Event Exit
32. In Section 5: Check mark the Short Stochastic Exit
33. In Section 6: Input 120 Rise Event NetChg
34. In Section 6: Input 1 Rise Event ROC
35. In Section 6: Input 5 Min Above Zero ZScore
36. In Section 6: Input 120 Fall Event NetChg
37. In Section 6: Input 1 Fall Event ROC
38. In Section 6: Input 5 Min Below Zero ZScore
In this configuration we are trading in long only mode and have enabled downward pyramiding. The purple trend line is based on the day (1440) period. The length is set at 90 days so it’s going to take a while for the trend line to alter course should this symbol decide to node dive for a prolonged amount of time. Your trades will still go long under those circumstances. Since downward accumulation is enabled, your position size will grow on the way down.
The performance example is Bitcoin so we assume the trader is buying coins outright. That being the case we don’t need a stop since we will never receive a margin call. New buy signals will be generated when the price exceeds the magnitude and speed defined by the Event Net Change and Rate of Change.
Feel free to PM me with any questions related to this script. Thank you and happy trading!
CFTC RULE 4.41
These results are based on simulated or hypothetical performance results that have certain inherent limitations. Unlike the results shown in an actual performance record, these results do not represent actual trading. Also, because these trades have not actually been executed, these results may have under-or over-compensated for the impact, if any, of certain market factors, such as lack of liquidity. Simulated or hypothetical trading programs in general are also subject to the fact that they are designed with the benefit of hindsight. No representation is being made that any account will or is likely to achieve profits or losses similar to these being shown.
